

Escrito por Fernando Maciá
Índice
- El principio del fin de las keywords
- Indicadores que se han visto afectados
- Alternativas obvias: métodos de extrapolación de datos
- Limitaciones de los métodos de extrapolación de datos
- ¿Cuáles son, entonces, las alternativas?
- Consultas de búsqueda en Google Webmaster Tools
- Palabras clave en Google AdWords
- Análisis de la búsqueda interna
- Google Keyword Planner
- Modelos “landing-page céntricos”
- Conclusiones
El principio del fin de las keywords
El 18 de octubre de 2011, Google anunció a través de su blog de Google Analytics así como su Blog Oficial de Google que el uso del buscador para usuarios con sesión abierta en Google se realizaría, a partir de ese momento, en el entorno de un servidor seguro (SSL).
 En la práctica, para los usuarios esto suponía que toda la información que viajara por la red entre el usuario del buscador y Google pasaba a quedar encriptada, tanto la propia búsqueda como la página de resultados del buscador. Para los propietarios de los sitios web, esto significaba que la información sobre las búsquedas de los usuarios que originaban estas visitas desde buscadores pasaban a estar encriptadas y, por tanto no disponibles, es decir, Not provided en cualquier sistema de analítica web.
En la práctica, para los usuarios esto suponía que toda la información que viajara por la red entre el usuario del buscador y Google pasaba a quedar encriptada, tanto la propia búsqueda como la página de resultados del buscador. Para los propietarios de los sitios web, esto significaba que la información sobre las búsquedas de los usuarios que originaban estas visitas desde buscadores pasaban a estar encriptadas y, por tanto no disponibles, es decir, Not provided en cualquier sistema de analítica web.
Este dato, que durante tantos años había sido clave en el trabajo SEO, quedaba así oculto para un porcentaje en principio reducido de las visitas pero que, con el tiempo, ha ido aumentando progresivamente. Aunque se especuló sobre la posibilidad de que este comportamiento fuera exclusivo de Google Analytics y de que se pudiera acceder a esta información vía otras soluciones de analítica web como Omniture, Piwik, Google Analytics Premium, o bien a través de la más clásica analítica a partir del registro del servidor (log), lo cierto es que, dado que la encriptación se produce en origen y, además, los resultados pasan por una redirección dentro del propio buscador, ninguna de estas alternativas es válida ya que no podemos realmente acceder al referrer original de la página de aterrizaje a la que llega la visita procedente de la página de resultados del buscador.
En septiembre de 2013, además, Google extendió la búsqueda segura a todos los usuarios, estuvieran con sesión abierta o no en el buscador. Esto supone que nos acercamos a un panorama donde el 100% de las búsquedas serán Not provided, ya que también otros buscadores han anunciado su intención de implementar la búsqueda en entorno seguro por motivos de protección de la privacidad de sus usuarios.
Indicadores que se han visto afectados
El hecho de que ya no tengamos acceso a las búsquedas que originaron las visitas procedentes de los resultados naturales de búsqueda ha afectado a distintos indicadores relacionados con la actividad SEO. En especial, a los siguientes:
- Palabras clave: evidentemente, Not provided es un cajón de sastre en el que perdemos la singularidad de multitud de palabras clave específicas que nos daban pistas valiosísimas sobre la intención de búsqueda de los usuarios.
- Amplitud de la visibilidad: uno de los indicadores clave en SEO era para qué número total de búsquedas únicas habíamos recibido tráfico orgánico en un mes. En teoría, una optimización de la arquitectura de un sitio web frecuentemente resultaba en una mejor visibilidad –mejores posiciones en los resultados– para una mayor variedad de búsquedas distintas. El indicador más claro de esta mejoría era que el total de búsquedas únicas que a lo largo de un mes habían generado tráfico orgánico aumentaba. Frecuentemente, se partía de un cierto umbral mínimo de visitas por palabra clave para descartar visitas desde clics erróneos o desde resultados poco relevantes.
- Branded SEO vs. NonBranded SEO: el objetivo esencial de una campaña SEO se ha centrado siempre en aumentar el número de nuevos visitantes, es decir, usuarios que no incluían en su consulta la propia marca de la empresa o el producto. Aunque hay ciertos sectores para los que es igualmente difícil competir para las búsquedas con marca (branded SEO) como el sector viajes, lo más habitual es que el posicionamiento trate de competir para las búsquedas sin marca, a costa de arrebatar cuota de mercado, en forma de clientes que no han expresado preferencia por una u otra marca, a nuestros competidores. Conocer qué parte del tráfico procedía con búsquedas de marca y sin marca permitía al cliente identificar el grado de reconocimiento y memorización de su marca entre su público objetivo y segregar cuánto de su tráfico orgánico se debía atribuir a su inversión en reconocimiento de marca (branding) y cuánto al expertise de su SEO.
- TrueDirect y TrueOrganic: desde siempre, en SEO hemos sabido que una parte del tráfico identificado por Google Analytics como orgánico procedía de usuarios que introducían el propio dominio del sitio web en el campo de búsqueda del buscador, lo que claramente indicaba la intención de los usuarios de visitar un dominio conocido a través de esa búsqueda navegacional. A través de segmentos personalizados, podíamos detectar este tipo de visitas mediante reglas restando este tráfico incorrectamente etiquetado como orgánico y añadirlo al tráfico directo, que es lo que realmente era. El NotProvided impide que realicemos esta corrección sobre los datos de Google Analytics. Todas las visitas procedentes de un buscador, también estas búsquedas navegacionales coincidentes con el dominio, serán registradas erróneamente como orgánicas.
- Búsquedas head vs. long tail: el análisis del número total de visitas por palabra clave nos permitía clasificar la visibilidad de un sitio Web entre palabras clave genéricas, semigenéricas y long-tail. Se trata de categorías de palabras clave distintas, pues un dominio recién publicado habitualmente se va posicionando inicialmente para búsquedas long-tail, logrando mejores posiciones en búsquedas más genéricas conforme adquiría autoridad y popularidad.
- Indicadores de calidad de visita por palabra clave de origen: es decir, analizar el comportamiento de los usuarios en función de su búsqueda nos permitía identificar qué búsquedas generaba el tráfico de mayor calidad a través, principalmente de los siguientes indicadores:
- Promedio de páginas vistas/sesión por palabra clave
- Promedio de tiempo de permanencia/sesión por palabra clave
- Tasa de rebote por palabra clave
- Tasa de conversión por palabra clave
- Cuota de mercado o penetración por búsqueda
Alternativas obvias: métodos de extrapolación de datos
Desde que las búsquedas Not provided comenzaron a aparecer en la analítica web, analistas y SEOs han tratado de encontrar alternativas para identificar las palabras clave que se esconden tras esta expresión genérica.
Algunos métodos iniciales se apoyaban en la extrapolación de datos. Es decir, a partir de las visitas de las que sí conocíamos las búsquedas que las habían originado, se trataba de tomar estas búsquedas como muestra representativa del total de búsquedas que habían originado todas las visitas orgánicas. De forma que, al menos teóricamente, si repartíamos todas las visitas marcadas como Not provided de forma proporcional entre las búsquedas conocidas, los datos resultantes debían acercarse a la realidad. Aunque lo cierto es que esto tampoco nos aportaba ningún dato cualitativo adicional. Las palabras clave únicas totales seguían siendo las mismas y en la misma proporción. Sólo variaban las cantidades de visitas atribuibles a cada búsqueda. En la práctica, algo no muy útil.
Sobre esta línea de trabajo, algunos autores propusieron métodos más refinados. Por ejemplo, Avinash Kaushik proponía en noviembre de 2011 realizar una extrapolación a partir de segmentos de visitas cuyo comportamiento presentaran indicadores similares, interpretando por separado el tráfico de búsquedas con marca (Branded SEO), búsquedas sin marca (nonBranded SEO), búsquedas genéricas y búsquedas long-tail en función de páginas de aterrizaje, indicadores de calidad de la visita, etc.
Según el método propuesto por Avinash, podríamos asimilar que una visita Not provided había llegado con una determinada palabra clave si había entrado al sitio web por la misma landing page y presentaba indicadores cualitativos similares a visitas de las que sí conocíamos la búsqueda de origen.
Limitaciones de los métodos de extrapolación de datos
Aunque en el propio anuncio de la implementación de la búsqueda segura en el blog de Google Analytics, Amy Chang apostaba por que el Not provided afectaría sólo a una minoría de las visitas, lo cierto es que dado el incremento en el uso de servicios de Google –GMail, Analytics, Google Webmaster Tools, Google+, Google Drive, etc.– el porcentaje de visitas de las que ignoramos la búsqueda que las originó no ha hecho sino aumentar, convirtiéndose habitualmente en la referencia mayoritaria dentro del apartado de Palabras clave de nuestro sistema de analítica web, sea cual sea.
Y esto significa que cualquier método que trate de representar la totalidad de una realidad a partir de una muestra representativa de la misma pierde fiabilidad a partir del momento en que el tamaño de esa muestra disminuye en comparación con el volumen global de datos que trata de representar.
Si asumimos que a corto plazo el volumen de búsquedas Not provided se acercará al 100%, cualquier método que use la extrapolación de datos a partir de los conocidos dejará de tener validez por lo reducido de la muestra.
¿Cuáles son, entonces, las alternativas?
En primer lugar, creo que deberíamos plantearnos la siguiente pregunta: si los buscadores han iniciado el camino hacia la búsqueda semántica, ¿seguirán teniendo las palabras clave la importancia que han tenido hasta la fecha en el proceso de búsqueda? Y me refiero tanto en lo referente a la forma en que los buscadores serán capaces de interpretar semánticamentee los contenidos como también a la forma en que serán capaces de interpretar la intención de búsqueda latente tras las expresiones de búsqueda introducidas por los usuarios.
En mi presentación Search Marketing: cuando el SEO ya no es suficiente expuesta durante los SearchDay de OMWeek en Madrid y Barcelona en otoño de 2013, me refería a la creciente importancia de la información que aporta el contexto, tanto de los contenidos como de las propias búsquedas de los usuarios. Y proponía algunas metodologías alternativas para tratar de interpretar cómo una necesidad genera una intención de búsqueda que el usuario interpreta en forma de consulta en un buscador para acceder al contenido que, o bien dará respuesta a su necesidad –en cuyo caso es probable que se produzca una conversión– o bien no lo hará –en cuyo caso se producirá un rebote (Figura 1).

Vamos a analizar qué podemos saber con estas alternativas y cuáles son sus limitaciones.
Consultas de búsqueda en Google Webmaster Tools
En Google Webmaster Tools, tenemos acceso a las búsquedas más importantes hasta un límite de unas 2.000 diarias, lo cual es suficiente para muchos sitios web. Podemos consultar los datos de palabras clave en las que alguna página de nuestro sitio se incluyó entre los resultados así como los clics obtenidos, datos a partir de los cuales también obtenemos el CTR.
Podemos consultar, en lugar de las consultas más populares, las páginas de entrada. A partir de este dato, podemos identificar qué búsquedas originaron visitas a qué landing pages.
Por ejemplo, si analizamos para un periodo determinado el tráfico orgánico que llegó al sitio web de Human Level aterrizando en nuestro post sobre la crisis de reputación online sufrida por Mercadona a raíz de su mención en el programa televisivo Salvados podemos comprobar que recibió 114 visitas. Vamos a Comportamiento > Contenido del sitio > Páginas de destino y segmentamos por Tráfico de búsqueda gratuito. A continuación, seleccionamos la página de entrada que nos interesa y aplicamos Dimensión secundaria > Palabra clave. Vemos que nada menos que 97 de estas 108 visitas fueron Not provided, es decir, desconocemos las palabras clave que originaron el 90% de las visitas a nuestra web a través de esta página:
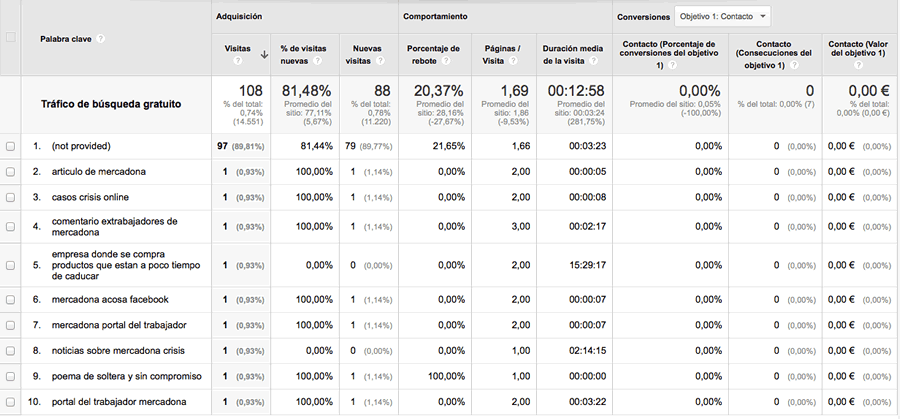
Si analizamos la misma página en las consultas populares de Google Webmaster Tools para el mismo periodo (seleccionamos Tráfico de búsqueda > Consultas de búsqueda > Páginas principales y utilizamos los Filtros para encontrar la página de entrada que nos interesa):

Vemos en la figura 3 que GWT registra un número ligeramente superior de clics que el total de visitas registrado por Google Analytics (127 vs. 108). Esto se debe a la distintas formas en que cada herramienta recopila los datos (GWT en el momento en que se presenta la información al usuario y éste hace clic sobre el enlace de la página de resultados y GA en el momento en que la página de aterrizaje se muestra en el navegador del usuario, además de otros factores como el ajuste horario de cada herramienta, etc.) En general, GWT debería registrar más clics que GA.
Lo llamativo de esta comparativa es que, aunque GWT registra el total de clics y el total de impresiones que hemos logrado para una determinada página, sólo registra las consultas principales. Por ello, la suma de clics registrada por la herramienta para cada palabra clave por separado no coincide con el total de clics registrados para el total de consultas que generaron clics sobre la página de aterrizaje. Y por eso las consultas que aparecen en Google Webmaster Tools no coinciden tampoco al 100% con las que sí podemos ver en Google Analytics, aunque guardan un cierto grado de semejanza (algunas de estas búsquedas, parecen registradas en momentos distintos de refinamiento de la misma búsqueda como, por ejemplo, “poemas con marcas de productos” en GWT y “poema de soltera y sin compromiso” en GA, lo que nos induce a pensar que en búsquedas donde se producen sucesivos comportamientos de refinamiento, la búsqueda registrada por ambas herramientas varía (GWT registraría la primera, mientras que GA registraría la última).
Limitaciones de Google Webmaster Tools
Las limitaciones de Google Webmaster Tools están claras:
- Tiene un límite en torno a las dos mil búsquedas principales diarias. Los clics registrados más allá de estas dos mil búsquedas quedan registrados, pero no las búsquedas que los generaron. En cualquier caso, este límite puede no ser un hándicap para muchos negocios que están por debajo de estas cifras.
- Sólo podemos acceder a los datos de los tres últimos meses. Esta es una limitación que podemos solucionar en cierta medida descargando periódicamente los datos de GWT. Algo que podemos automatizar usando Python.
- Hay diferencias patentes entre las palabras clave registradas por GWT y GA, por el distinto momento en que se registra la búsqueda (primera búsqueda vs. búsqueda refinada).
No obstante, y dado que en GWT no queda reflejado ningún dato personal (toda la información es agregada) podríamos pensar (o, al menos, desear) que en el futuro Google elimine la limitación a mostrar sólo las búsquedas principales y ese límite de dos mil consultas diarias, de forma que sí nos muestre datos mucho más cercanos a los que hemos perdido en Google Analytics.
Palabras clave en Google AdWords
Uno de los apartados de Google Analytics donde sí podemos seguir viendo las consultas reales que generaron tráfico a nuestro sitio web es el de Adquisición > Palabras clave > De pago > Consulta de búsqueda coincidente.
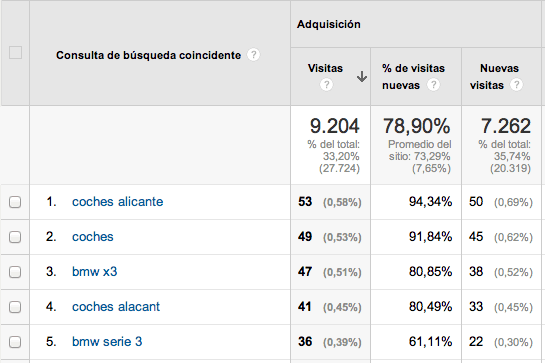
Si queremos obtener una información un poco más relevante, podemos seleccionar como dimensión secundaria Página de destino y así podríamos ver cómo se ha comportado el tráfico desde cada búsqueda al aterrizar en la página de destino. Datos cualitativos como el porcentaje de conversiones o el Valor por visita nos van a decir mucho sobre si deberíamos intensificar nuestros esfuerzos para lograr mejores posiciones orgánicas en esas palabras clave.
Si empleamos las mismas páginas de aterrizaje para nuestra estrategia SEO y PPC, esto nos debería dar información muy valiosa sobre que parejas de “palabras clave/páginas de aterrizaje” generan un mayor valor. Aunque esto no nos dice qué visitas llegaron de forma natural a esas páginas, sí nos ayuda a enfocar su relevancia para que se posicionen mejor para esas búsquedas de mejor comportamiento.
Si, por el contrario, manejamos grupos de páginas de aterrizaje específicos para PPC, podemos de todas formas aprovechar la información para identificar las áreas de fortaleza que están haciendo que esas landing pages funcionen bien en PPC y aplicar los mismos criterios sobre nuestras páginas de entrada de tráfico orgánico.
Avinash Kaushik propone un informe personalizado para Google Analytics con el que podemos desglosar las búsquedas reales que emplearon los usuarios antes de hacer clic en un AdWords. Podemos analizar por separado las búsquedas que se ajustaron por concordancia amplia, de frase o exacta.
Limitaciones de Google AdWords
Las principales limitaciones de Google AdWords son las siguientes:
- Evidentemente, la primera es que no tendremos ningún dato si no invertimos en Google AdWords, así que el coste sería la primera.
- En segundo lugar, el comportamiento del tráfico procedente de AdWords no es totalmente asimilable al tráfico que viene por resultados naturales.
- En tercer lugar, una campaña de PPC habitualmente exige trabajar con grupos de palabras clave, anuncios y páginas de aterrizaje perfectamente coordinados. Necesitaremos un trabajo extra para identificar qué virtudes de nuestras landing pages para PPC son trasladables a nuestras páginas de entrada SEO.
Análisis de la búsqueda interna
Uno de los lugares donde podemos seguir viendo qué buscan los usuarios es en la búsqueda interna en nuestro sitio Web. Esta información se encuentra disponible en Google Analytics, en Comportamiento > Búsquedas en el sitio > Términos de búsqueda. Eso sí, antes habrás tenido que configurar el rastreo de búsquedas internas por la herramienta desde Administrador > VER > Ver configuración activando la opción correspondiente en Seguimiento de búsqueda en el sitio.
El valor de esta información será más o menos relevante en función de la dimensión del sitio Web. Si hablamos de un comercio electrónico con decenas de familias de productos y miles de referencias, es más probable que los usuarios usen el buscador interno sin que ello sea un indicio de una mala arquitectura o una navegación poco usable.
Esta información nos puede dar ideas, por ejemplo, sobre:
- Qué esperaban encontrar los usuarios en nuestro sitio web y no identifican en el menú una forma más rápida de navegar hacia dicho contenido.
- Páginas que no responden a las expectativas de los usuarios, si activamos Página de de inicio como dimensión secundaria.
- Errores ortográficos a la hora de denominar ciertos productos, categorías, marcas…
- Taxonomías preferidas por los usuarios a la hora de especificar categorías o productos en sus búsquedas.
- Indicadores de calidad del comportamiento post-búsqueda, si activamos Página de destino como dimensión secundaria.
Limitaciones de la búsqueda interna
El comportamiento del usuario una vez está en un sitio web es completamente distinto de la actividad propia de la búsqueda en un buscador. Las conclusiones que podemos extraer de estos análisis no deberían extrapolarse más allá de interpretar carencias en la navegación o descubrir patrones de búsqueda.
Google Keyword Planner
Podemos usar la herramienta sugeridora de palabras clave de Google AdWords para descubrir cuáles son las búsquedas más populares que Google relaciona con mi contenido en un ámbito geográfico determinado.
Para ello, puedo partir de Planificador de palabras clave > Buscar nuevas ideas para palabras clave y grupos de anuncios:

Al pulsar sobre Obtener ideas, Google me devolverá los conceptos que el buscador entiende que, relacionados con mi contenido, al mismo tiempo son búsquedas populares para los usuarios de la segmentación geográfica y de idioma que he configurado. Por ejemplo, algunas ideas sobre cómo los usuarios buscarían una empresa de posicionamiento:

De esta forma puedo saber de qué forma puedo seguir optimizando mi contenido para lograr mejores posiciones en las búsquedas más populares.
Limitaciones de Google Keyword Planner
De nuevo, la herramienta me dice hacia qué palabras clave debería optimizar mis páginas, pero no cuántos visitantes realmente llegaron con dichas búsquedas. Aunque debemos asumir que si logramos un buen posicionamiento para dichas búsquedas, cada vez lograremos que nuestro CTR para ellas se incremente (lo que podremos comprobar en Consultas de búsqueda en Google Webmaster Tools).
Modelos “landing-page céntricos”
Uno de los acercamientos más interesantes al análisis de lo que se esconde tras el Not provided ha venido de la mano de Iñaki Huerta, quien propuso un modelo “landing-centrista”. Recomiendo la lectura del post de Iñaki ya que me parece un acercamiento bastante razonable el que propone de trabajar por parejas o conjuntos de páginas de entrada/palabras clave asociadas. El post aporta además métodos para facilitar la identificación más intuitiva y rápida de las páginas de entrada con sus palabras clave asociadas en Google Analytics.
Lo que la metodología de Iñaki Huerta no resuelve –por otra parte, como ningún otro método descrito– es identificar de forma inequívoca las palabras clave que originaron las visitas que accedieron al sitio web a través de esas páginas de entrada, por mucho que nos hayamos esforzado en enfocar y posicionar dichas páginas en las keywords que les hemos asignado como objetivo de visibilidad.
Es realmente difícil que un contenido se posicione exclusivamente para una o dos palabras clave, por muy enfocado que esté ese contenido.
En línea con este modelo “landing-page céntrico”, en Human Level Communications hemos propuesto una metodología que trata de abordar este problema desde otra perspectiva. Los puntos de partida son los siguientes:
- Una página se posiciona habitualmente para más de una única palabra clave.
- Una página es visible en las SERPs cuando ocupa puestos top30.
- La mayor probabilidad de tráfico podemos atribuirla a las páginas que ocupan las mejores posiciones para las búsquedas más populares.
Con estos puntos de partida, se nos ocurrió cruzar datos de dos fuentes distintas: Google Analytics y SEMRush.
El método que proponemos es el siguiente:
1. Obtener tráfico orgánico Not Provided en Google Analytics: para lo cual, aplicamos segmento Tráfico de búsqueda orgánico, seleccionamos en Adquisición > Palabras clave > Orgánica y hacemos clic en Not provided.
1.2. Exportamos en formato CSV o Excel que abrimos o importamos en Excel o Numbers.
2. Obtener palabras clave donde aparecemos en puestos top20 con SEMRush: para lo cual, introducimos el dominio a analizar y vamos al informe Palabras clave orgánicas.
3. Emparejamos Páginas de destino y palabras clave a través de una búsqueda vertical: se trata de encontrar, para cada página de destino de nuestra pestaña de Google Analytics Not Provided, la palabra clave más popular y mejor posicionada para la que dicha página está posicionada, según SEMRush.
3.2. Introducimos una fórmula que buscará cada URL de Analytics en la pestaña de los datos de SEMRush. Cuando haya coincidencia, rellenará el campo con la palabra clave correspondiente a esa página de entrada.
3.3. La fórmula para Numbers es:
=CONSULV(valor_buscado;matriz_buscar_en;indicador_columnas;[ordenado])
3.4. La fórmula para Excel es:
=BUSCARV(valor_buscado;matriz_buscar_en;indicador_columnas;[ordenado])

4. Podríamos llevar más allá este método si distribuimos proporcionalmente todas las visitas Not provided entre las múltiples palabras clave para las que está posicionada una página de destino concreta de forma directamente proporcional a la popularidad de dicha búsqueda (un dato que SEMRush aporta) e inversamente proporcional a la posición que ocupamos para ella (un dato aproximado que también aporta SEMRush).
Limitaciones de nuestro modelo
Parecería muy bonito que este modelo funcionara perfectamente como lo hemos descrito. Lamentablemente, también tiene sus limitaciones:
- SEMRush sólo detecta posiciones top20, así que no podremos saber para qué otras palabras clave está posicionada una URL por debajo de ese límite.
- SEMRush no puede detectar de forma exhaustiva todas las palabras clave para las que una página está posicionada. SEMRush utiliza una muestra de búsquedas y trata de emparejar las más relevantes en función del contenido detectado en la página. Pero lo cierto es que casi todas las páginas se posicionan para una mayor variedad de búsquedas de las que SEMRush puede detectar, aunque nos parece un muy buen punto de partida.
- SEMRush tampoco analiza la totalidad de páginas de un sitio Web, ya que algunas o muchas de nuestras páginas no tendrán posiciones top20 para alguna de las búsquedas muestreadas por SEMRush.
Por ejemplo, para la URL analizada anteriormente sobre Mercadona, éstas son las palabras clave y posiciones extraidas de SEMRush:

En las que echamos en falta palabras clave sí presentes tanto en Google Webmaster Tools como en Google Analytics.
Conclusiones
Aunque son ejercicios de reflexión estimulantes y en muchos casos nos pueden ayudar a entender mejor las búsquedas con mayor potencial e incluso la intención de búsqueda de nuestros usuarios, lo cierto es que estos datos no nos los puede devolver más que quien nos los quitó.
Mi mejor apuesta sería por que los buscadores compartan los datos registrados en las propias SERPs a través de Google Analytics, eso sí, sin muestreo ni límite y de forma exhaustiva. De esa forma nos estarían aportando el conocimiento que necesitamos del mercado sin comprometer en forma alguna la privacidad de los usuarios.
Y, en cualquier caso, deberíamos preguntarnos, para empezar, si en el universo de la búsqueda semántica hacia el que nos encaminamos el concepto de palabra clave seguirá manteniendo su vigencia. Las búsquedas introducidas por los usuarios en los terminales móviles, conforme aumenta su uso, serán distintas de las que se introducen en un teclado físico. Y éstas serán también distintas cuando se generalice el uso de interfaces de voz, ya que dictaremos búsquedas mucho más específicas libres del engorro de teclear. Y ante refinamientos sucesivos de la búsqueda como el ejemplo puesto por Google para Hummingbird (¿Quién es Leonardo diCaprio? > ¿Cuándo se casó?), ¿cuál será la palabra clave que quedaría registrada? ¿Tendría algún sentido?




Cada vez el SEO es más complicado, como en el caso del Not Provided como comentas, pero esto nos hace que tengamos que seguir mejorando profesionalmente, olvidar antiguas técnicas y centrarnos más en los clientes que en los buscadores.
Saludos!
Gracias por tu comentario Miguel. Efectivamente, aunque saber cómo funcionan los buscadores y sus limitaciones nos ayuda mucho en SEO.
Hola,
Un artículo muy extenso en el que se explica con mucho detalle como podemos analizar el tráfico que se genera en nuestro sitio Web.
El GWT se ha convertido en una herramienta imprescindible para analizar el trabajo de cualquier SEO, por supuesto combinándolo con el Google Analytics o otras herramientas de análisis.
Enhorabuena por el post.
Un Saludo.
Hola Rafa, gracias por tu comentario. Por supuesto, el Google Webmaster Tools es insustituible, junto con Google Analytics. Y ya ves que para el Not provided es muy útil contar con herramientas con SEMRush que no me canso de recomendar. Con los datos de SEMRush cruzados con los de Google Analytics, podemos ver mejor qué se esconde detrás del not provided.
Completísimo Fernando, da gusto ver un artículo tan detallado y sobre todo práctico que englobe todas las acciones y situaciones que se pueden analizar, detectar y adecuar para la estrategia online que sigamos.
Añado el blog a mi Feedly que no os tenía controlados 🙂
Que paséis un buen día,
Roger.
Muchas gracias por tu comentario, Roger. Espero que te sea útil nuestra metodología para atacar el not provided y poder así controlar mejor las búsquedas que están detrás de nuestro tráfico natural. Un abrazo.