

Written by Rocío Rodríguez
Index
What is the sitemap file?
The sitemap is a file that includes a list of all the relevant pages of your site along with additional information about them, such as how often the information on a page changes, when it was last updated, or the importance of a particular URL in relation to the rest of the pages on the site. The frequency of modification of the content of a page tells Google how often these pages of the site should be crawled.
The purpose of this file is to help search engines find and index the pages of your website. As a general rule, crawlers index all the pages they find, unless they include some kind of blocking instruction.
There are several sitemap formats but the most used is the one containing the XML extension. Sitemap files can be created manually or using third-party tools for their generation, such as programs (e.g. XML Sitemap Generator) or specific plugins for each content management system (e.g. there are some for WordPress or Drupal).
The creation of the sitemap file is not mandatory, but it is recommended. All webmasters should consider its generation for those websites that have not yet contemplated its inclusion. It is important that we pay attention to Google’s specifications and requirements during sitemap generation to avoid any type of error or problem. If errors or warnings still appear after its creation, it is important that we analyze and fix them carefully so that Google can access and process this file correctly.
How do the spiders find the pages of our site?
Search engines discover new pages through links, both external and internal. For example, if we have created a new landing page and it contains no inbound links and we have not linked to it internally from the website, Google will not be able to find it and therefore will not be able to index it. However, it can also happen that a page is correctly linked from the site but is very deep in the hierarchy so that it can be difficult for crawlers to reach it.
With the sitemap file we make it easier for search engines to locate and discover your site. However, we must keep in mind that the inclusion of the pages in this file does not ensure their crawling and indexing. Pages withthin content are usually some of those URLs that, despite including and submitting them in the sitemap, the search engine may not end up indexing. They are usually tag pages, listing URLs with 2 or less products, etc.
All those pages that have not been found and crawled cannot be added to the Google.es index and, therefore, cannot be returned as a result of a relevant search performed by the user.
Typology of sitemaps
There are different types of sitemaps to describe multimedia and other content that can be complex for search engines to analyze.
Video
Video sitemaps allow us to inform search engines about the video content on our site. This is information that spiders would not be able to identify using the usual crawling mechanisms. In this way we will be able to improve the visibility of the site for searches made from Google Videos.
A sitemap video entry can specify the length, category and recommended age rating of the video.
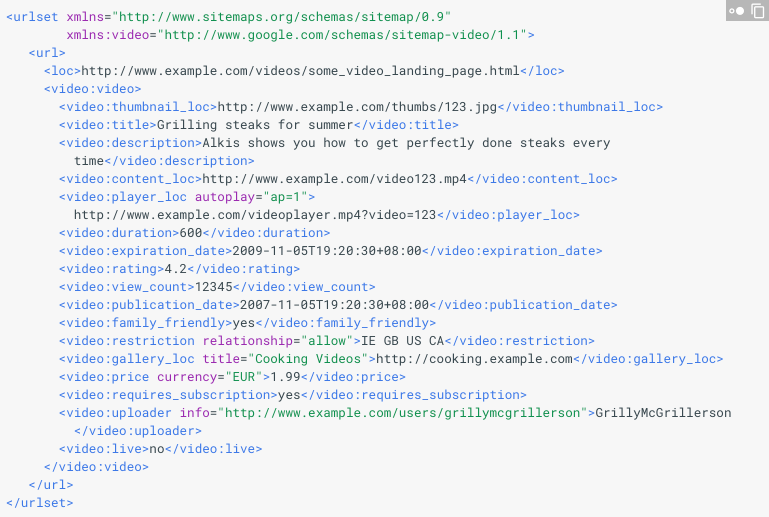
However, we can also indicate video content in an existing sitemap without having to create a separate one for videos.
Image
This type of sitemaps will improve our visibility for searches performed from Google Images, by allowing the images of our site to be crawled and indexed by the spiders. This is information that spiders would not be able to identify using the usual crawling mechanisms.
A sitemap image entry can include the subject, type and license of the image.
We can use a separate sitemap to include images or add image information to an existing sitemap.
Websites where it would be convenient to have a sitemap of images would be, for example, tourist portals, recipe pages or online stores.
If we do a Google Image search for the recipe “Chicken with almonds” we will see that a large list of results with images of the dish will appear. Each of these images has its own URL:
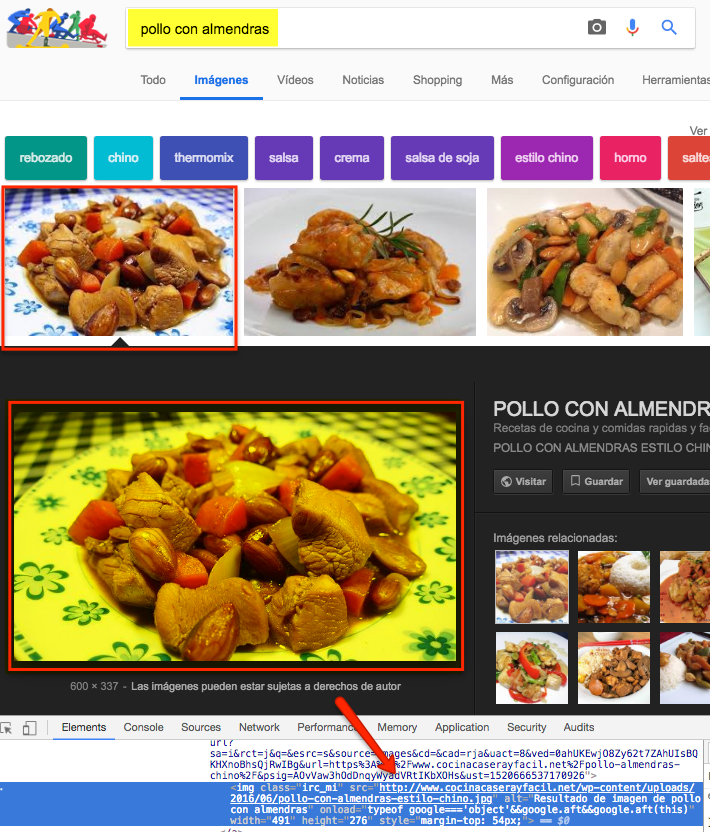
In the case of the first result we can see how the address of the image has been included in one of the sitemaps of the site:
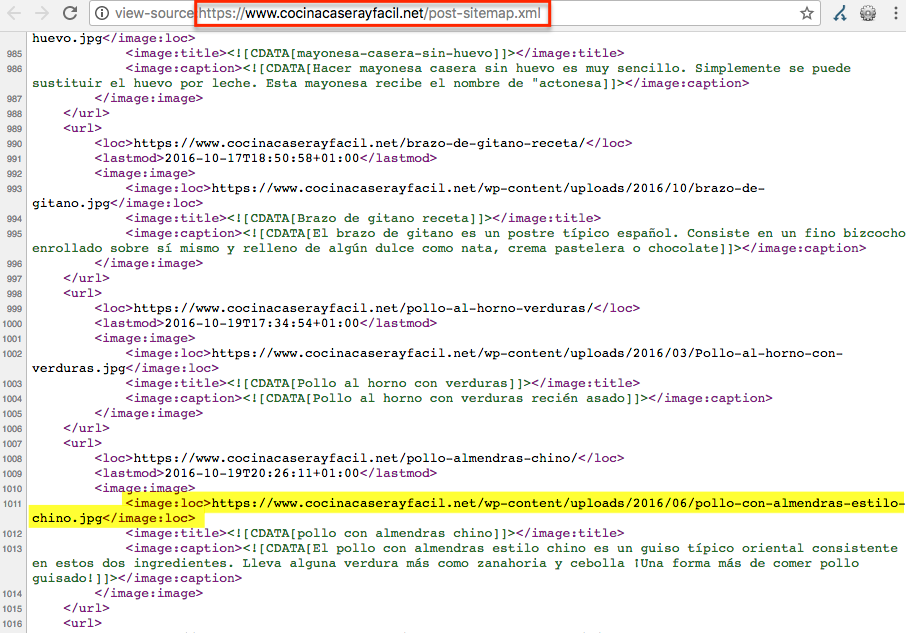
This practice is facilitating the crawling and indexing process of the image by search engines and is, in turn, improving our visibility for certain searches in Google Images.
News
This type of sitemap is often used to speed up the news discovery process for spiders.
This sitemap is slightly different from the one containing the web pages. It has specific tags such as the <news:keywords> or the <title>. The tag <title> is mandatory and must contain the title of the news item as it appears on the website. The <news:keyword> is not mandatory but recommended. The crawlers use the terms included in it to classify the news. This allows our article to rank for related searches for which we wish to gain visibility.
We do not recommend using more than 8 keywords in this sitemap tag. On the other hand, we must bear in mind that the order of inclusion of the terms does not determine their importance; they would all be at the same level of relevance.
We can also find the stock tickers label, which is used for economic news.
News sitemap files cannot contain more than 1,000 URLs or include articles older than 24 hours, always counting from the date of publication. However, they will still be able to appear in Google News for a period of 30 days.
This would be the syntax of a news sitemap:
 This will favor us in terms of positioning, since if search engines discover our page shortly after it has been published, we will have a better chance of positioning ourselves for current searches just at the moment when they reach their peak of traffic.
This will favor us in terms of positioning, since if search engines discover our page shortly after it has been published, we will have a better chance of positioning ourselves for current searches just at the moment when they reach their peak of traffic.
For the generation of news sitemaps Google sets a series of guidelines that must be met. We recommend reviewing these requirements if we are considering generating a sitemap of this type for our site.
Improving the indexing of your site
The sitemap consists of a series of tags, some of which are optional: <lastmod>, <changefreq> y <priority>. These are shown in italics below:
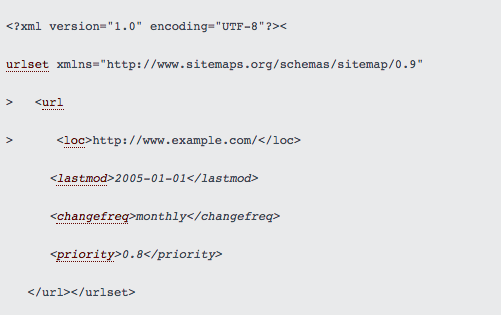
These optional tags, which we will discuss below, will allow us to provide relevant information about our pages to search engines, which will help them during their crawling and indexing process.
Prioritization of pages within a site
The tag <priority> indicates to search engines the importance of a URL in relation to the other pages of the site. This suggestion does not affect the ranking of your pages in Google.com results. The values of this label range from 0.0 to 1.0.
As stated in Google’s documentation, “this value does not affect the comparison of your pages with those of other sites; it only allows you to inform search engines of the pages you consider most important to crawlers“.
Frequency of update of each page
The tag <changefreq> is also optional and indicates how often the page changes. The accepted values for this label are:
- always (documents that change each time they are accessed)
- hourly
- daily
- weekly (weekly)
- monthly
- yearly (annually)
- never (must be used for archived URLs)
However, it should be noted that the information contained in this tag acts as a suggestion and not as an absolute directive, so crawlers may take this information into account or ignore it. For example, it would not be uncommon to find daily crawls on URLs that are marked as <changefreq>hourly</changefreq>. Similarly, spiders may crawl more frequently other pages marked as <changefreq>yearly</changefreq>.
Date of modification
As its name suggests, the tag <lastmod> indicates the date the page was last updated. The date must be in W3C date and time format.
Accessible URLs
All URLs in the sitemap must be accessible, i.e. any robot should be able to access them. Therefore, we will avoid the inclusion of pages that have been blocked from the robots.txt file or from the robots tag in the HTML code.
In the case of the latter, we must bear in mind that it may be incongruous for Google if, on the one hand, we are sending the pages in the sitemap to be crawled and indexed and, on the other hand, we are indicating that we do not want it to index it by configuring the value “noindex” in the robots meta tag of the HTML code of the page. This practice should be avoided if optimal saturation figures are to be achieved.
Pages returning response codes other than 200
All URLs included in the sitemap must return 200OK status codes. We will avoid including pages with any 400 response codes or URLs with redirects of any kind (301, 302, etc).
Pages with session IDs or other URL parameters
We should avoid including URLs with session identifiers as this is a duplication of the original page. This will limit the crawl to relevant URLs while reducing the crawl of duplicate pages that do not provide value in terms of positioning.
Parameterized URLs should also be ignored. These pages usually present all or part of the content of the original page but sorted through a filter added by the user: price, color, brand, etc. These are therefore URLs that would display information identical or similar to that of the page without parameters. The inclusion of these pages in the sitemap could cause the crawling of duplicate pages or URLs of little relevance to our site that we do not want the spiders to crawl and index.
Sitemap update
The sitemap must be updated so that it always contains the new URLs of our site. There must be a coherence between the content that we indicate to the spiders that they have to index with the content on our website.
The update frequency will vary depending on the website (it can be a media, a blog, an online store, etc…) and the regularity of its publications. In the case of a media company, the sitemap should be updated on a daily basis, since it is optimal for this file to include all the URLs of the new news or articles that are published. On the other hand, if it is an online store, the update frequency will not be as frequent. However, as this is a website where products are constantly being renewed (some products are discontinued, new ones are added, etc.), we must make sure that the sitemap file is kept up to date.
We can make use of plugins for automatic sitemap updating. It is also possible to update this file manually, although the process can be more arduous and complex.
Multi-language sites
If your portal is multilingual, you should have a sitemap for each language uploaded in its corresponding Search Console root and profile, whenever possible.
Sitemap size
The sitemap must not exceed 50MB (52,428,800 bytes), either compressed or uncompressed, nor contain more than 50,000 URLs. This will ensure that the web server does not crash when serving a large number of files.
If your site has more URLs than the ones mentioned above or if your sitemap exceeds the maximum recommended size, you will need to create several sitemap files that you will manage through a sitemap index file.
For sitemap compression Googlerecommends using the gzip format instead of zip.
Administration of several sitemaps
Simplify the management of your sitemaps with the sitemap index file. The sitemap index file allows you to send all sitemaps at once so it can make the process much easier for you.

This option is usually quite useful in large sites, such as some media that upload news indexes by months of the year, but also for other portals that, even if they are not so large, have a large number of sitemaps.
We often come across sitemaps with a response time that is too high, a situation that can directly affect the indexing of the pages contained therein. In this case it is best to divide the pages into several sitemaps. Managing all of them from the sitemap index will be very easy.
One option to properly organize the pages of an online clothing store would be to divide them as follows:
- Sitemap 1: category pages (men, women, dresses, pants, etc.)
- Sitemap 2: brand pages (Diesel, Desigual, Pedro del Hierro, Bimba y Lola, etc).
- Sitemap 3: blog posts
- Sitemap 4: blog tags
- Sitemap 5: products
- Sitemap 6: products
- Sitemap 7: products
- Sitemap 8: images
In this way we will be able to control the indexation of each sitemap separately and see if there are specific problems in each of these types of pages.
The sitemap index file can contain a maximum of 50,000 URLs and cannot contain other sitemap index files, only sitemap files.
Pages with little relevance
In the sitemap should be sent all relevant pages of the site that we want the spiders to crawl and index. We will avoid the inclusion of URLs that are of minor importance within the overall site architecture. We refer, for example, to the pages of cookies, privacy policy or terms of use. In this way we will focus all the strength on the URLs that we really want the crawlers to index. These URLs could be news pages, product sheets or site categories.
Check that your sitemap contains the correct pages
Before submitting the sitemap we must make sure that it includes the relevant URLs of the site, that is, those that we want Google to crawl and index. For this we can use tools such as Screaming Frog, from which we can download the sitemap file directly including the URL.
When the tool has finished crawling all the URLs, we should look at the “Status Code” column. Alarm bells should ring if we find status codes other than 200OK. Redirected pages, whether they are temporary or permanent redirects, should not be kept in the sitemap. We recommend removing them from this file. The procedure to follow will be the same in case we find non-existent pages (404, 410, etc).
Another indicator to check is the “Status”, which indicates whether the crawling of a certain page has been blocked from the robots.txt file of the site. We will have to check if this blocking instruction on these pages is really correct or if it has been included by mistake. It may also be the case that at the time we did not want it to be found by the crawlers but now we are interested in including it in their index. In case the blocking instruction was correct we should proceed to remove these URLs from the sitemap. Similarly, if we detect that some of the URLs are being blocked by mistake, it is recommended that we facilitate their crawling by removing them from the robots.txt.
Equally important is also to check the “Meta Robots” column, to identify which pages have the “noindex” instruction. URLs with either of these two blocking instructions should not be included in the sitemap file of the site. It is inconsistent that the same URLs that we are submitting in the sitemap for search engines to crawl and index, contain at the same time an instruction that blocks access to robots.
It is advisable to pay attention to these recommendations since, by correcting these errors, we would be able to improve the site saturation figures.
After correcting the issues found, we must resubmit the sitemap.
Sitemap Submission
You can add the sitemap to the root directory of your HTML server, that is, at http://midominio.es/sitemap.xml. Once the sitemap file is created, we must make it available to Google. From Search Console we can add, submit and test the sitemap by accessing the Crawl option > Sitemap, from the left side menu. In addition, we will be able to keep track of the files sent and detect possible failures, errors or warnings that are registered.
Another option is to include the URL of the sitemap file in the robots.txt of the site. It is sufficient to include the following line:
- Sitemap: http://example.com/ubicacion_sitemap.xml
However, this last option should be considered as a last resort. Anyone can have access to the robots.txt of your site, it is advisable that you do not offer them too much information that could be used against you.
Saturation monitoring
The saturation index is the ratio between the pages that we send to Google and those that it finally ends up indexing. This indicator can be consulted from Google Search Console, by accessing > Sitemaps tracking from the side menu of the tool.
As a general rule, this value never reaches 100%. However, we should try to keep the percentage as close to this figure as possible, as this will indicate that almost all of the pages submitted in the sitemap have been crawled and indexed by the spiders. The more relevant pages of our site are indexed, the more likely it is that the search engine will return them as a result of a relevant search performed by the user. Pages that Google does not index will not be found by users after a natural search, with all that this entails: loss of visits, pages that cannot be positioned, etc.
Common mistakes to avoid
- Send the sitemap empty: no matter how much we generate and send the sitemap file, if it does not contain the URLs that we want the crawlers to find, it will not help us in a positive way in terms of SEO.
- Exceeding the maximum allowed size: if it exceeds 50MB uncompressed we will have to create a sitemap index file and split it into several sitemaps.
- Include an incorrect date: we must ensure that the dates have the W3C date and time encoding (specifying the time is optional).
- Inclusion of invalid URLs: those with unsupported characters or symbols such as quotation marks or spacing. Or others that include the wrong protocol (HTTP instead of HTTPS).
- Duplicate tags: to solve this problem we must delete the duplicate tag and resubmit the sitemap.
- Too many URLs in the sitemap: make sure that it does not contain more than 50,000 URLs, otherwise split the sitemap index into several files taking into account that they should not contain more than 50,000 pages each.
- Do not specify complete URLs. The complete URL must be provided. For example, www.midominio.com would not be correct since we would be dispensing with the HTTP/HTTPS protocol.
- Send loose sitemaps. Include all your sitemaps in a sitemap index file.
- Inclusion of erroneous labels. We must make sure that all the sitemap tags are correctly written. Spelling errors such as putting <news:language> instead of <news:language> can cause the sitemap to register numerous errors and the search engines to be unable to process it correctly.



