

Escrito por Rubén Martínez
Índice
Para que un sitio web aparezca entre los resultados de búsqueda de un usuario de Google, debe cumplirse el requisito imprescindible de que las páginas de ese sitio estén incluidas en el índice del buscador. Explicado de forma muy general, el proceso por el cual Google es capaz de mostrar resultados tras una consulta, se divide en tres fases principales:
- Rastreo: Google encuentra páginas nuevas y las agrega a su índice.
- Indexación: lee el sitio y procesa su contenido.
- Publicación: tras la consulta, se inicia un proceso de selección de los resultados más apropiados donde entran en juego más de 200 factores que determinan la relevancia de cada uno, de forma que sea posible establecer una clasificación o ranking.
Es en las dos primeras fases en las que el gestor de una web tiene en su mano la posibilidad de intervenir en busca de un beneficio directo. Es por esto que, si deseamos que nuestro sitio pueda ser encontrado por quien realice búsquedas relacionadas, el primer paso que debemos dar es asegurarnos de que es adecuadamente rastreable e indexable.
Aportar contenido relevante e indexable
Es tan obvio como importante que una web contenga información relevante y con relevante me refiero a clara, específica y capaz de resolver problemas y satisfacer las necesidades del usuario. Pero esto no es todo, ya que hay unos requisitos técnicos que cumplir previamente para que, además de a los usuarios, el sitio web le guste a Google.
Una excelente manera (¿quizá la mejor?) de que el buscador tome buena nota de nuestra web y decida mostrarla en muchas ocasiones y en buenas posiciones, es intentar ser un punto de referencia dentro del sector, por lo que una recomendación clara en este sentido es enriquecer el contenido del sitio lo máximo posible aportando información valiosa para el usuario, donde las URLs, los títulos, la metas descripciones, los textos, los encabezados y las imágenes de cada página, formen núcleos de contenido relevante orientados a temas concretos y, a través de una distribución de enlaces internos, podamos trasladar a nuestra conveniencia la popularidad entre las páginas enlazadas. Este patrón se cumplirá independientemente de si se trata de un blog de viajes o de un comercio electrónico de antigüedades.
Pero, ¿qué ocurre si comenzamos a crear y publicar textos sin control ni estructura? Seguramente incurriremos en duplicidades de contenido, en páginas con contenido poco relevante, en contradicciones entre redirecciones 301 y etiquetas canonical, en una arquitectura de la información mal proyectada y en un enlazado interno sin un enfoque claro. Como ya hemos advertido con anterioridad en otros artículos, para llevar a cabo todos estos pasos de manera apropiada, se deberá realizar previamente una investigación de palabras clave que nos marque el camino a seguir en base a los términos más importantes del sector en el que trabajemos.
Cabe añadir que no todo el contenido de un sitio será necesariamente indexable. Es por ello que disponemos de diferentes recursos que nos ayudarán a indicar a Google lo que deseamos y lo que no deseamos que incluya en su índice.
Cuál es el contenido que no se debe indexar
Debemos tener en cuenta en todo momento que la saturación o porcentaje de páginas indexadas de nuestra web debe responder a una coherencia con el contenido relevante que tengamos en el sitio. Para ello, existen diferentes recursos que nos ayudarán a interponer bloqueos ya sea de forma puntual o definitiva a páginas e incluso secciones completas de la web. El instrumento por excelencia para este tipo de procesos es el fichero robots.txt, especialmente si es necesario restringir el rastreo de un gran número de páginas o un subdirectorio completo. Se trata de encontrar un equilibrio, sobre todo si estamos hablando de un portal de grandes dimensiones, en el que no malgastemos los recursos de las arañas y permitamos que se centren en lo verdaderamente importante.
Es muy común que, por ejemplo en WordPress, no queramos que se indexe el subdirectorio /wp-admin, correspondiente al área de administrador, ni las carpetas en las que se alojan los plugins y los temas, para lo cual será necesario incluir las siguientes líneas en el archivo robots.txt:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
No significa que todo aquello que no incluyamos en el fichero robots.txt se vaya a indexar, no obstante, si los rastreadores encontraran enlaces hacia estas secciones, serían muy susceptibles de ser incluidas en el índice si no hemos tomado las precauciones de bloquear estas páginas.
Atributo rel=”nofollow”
El atributo rel con valor nofollow es una característica que debemos saber aprovechar a la hora de conformar la red de enlaces internos. Se deberá incluir un nofollow a todos aquellos enlaces cuya página destino no deseamos que sea rastreada y por tanto indexada por el buscador, como por ejemplo los links al área privada. No incluir el atributo rel en un enlace hará que se considere como follow y por tanto será seguido por los robots.
Thin content o contenido insignificante
Las páginas cuya indexación queremos evitar son aquellas que no muestren al usuario contenido relevante. Por ejemplo, páginas de «no se han encontrado resultados» como la que vemos en la imagen siguiente en la web de Versace:
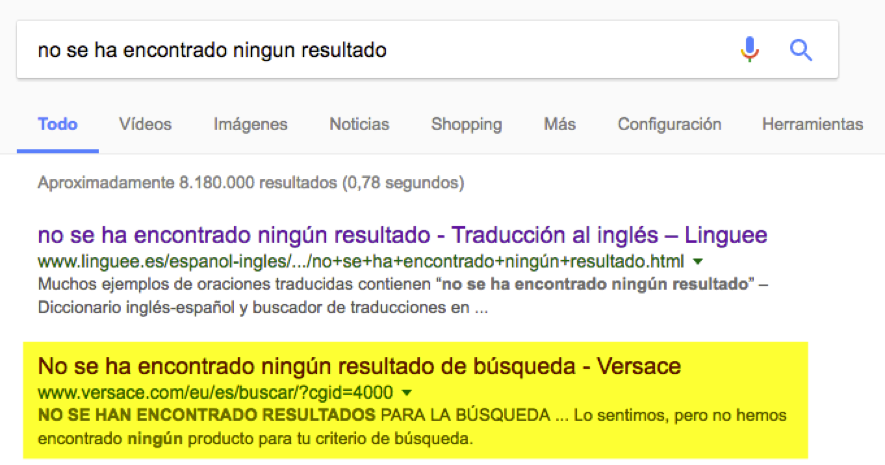
Al hacer clic en el segundo resultado, accedemos a una página sin contenido:
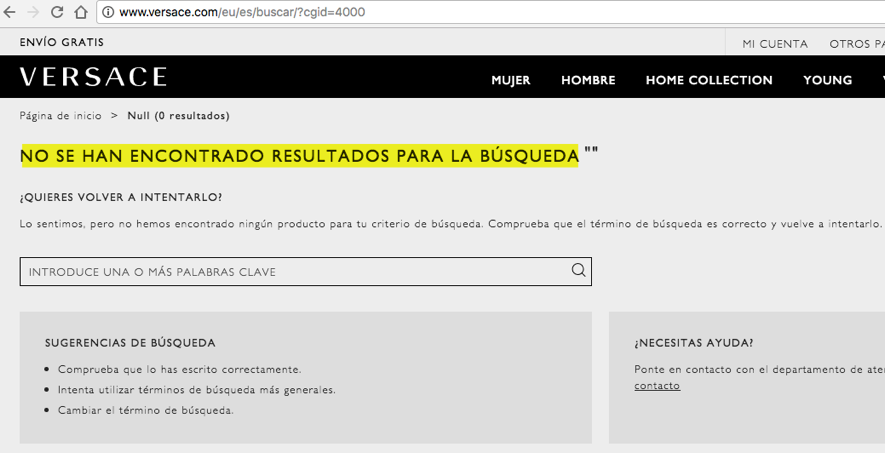
Bien es cierto que puede parecer absurdo realizar una búsqueda de este tipo, sin embargo, este es un ejemplo claro de que tampoco tiene sentido que Google dedique recursos a leer y guardar páginas sin ningún valor para el usuario, dado que el límite de rastreo es un parámetro que se establece internamente y si las arañas emplean tiempo en leer y almacenar secciones no relevantes, podría reducir la frecuencia de rastreo por considerar el sitio de baja calidad. En casos de un importante número de páginas de este tipo indexadas, se debe indagar con más profundidad para detectar la raíz de su generación y proceder a su bloqueo.
Otros casos se pueden dar, por ejemplo, en portales de banca, donde determinadas secciones deben permanecer desindexadas por seguridad, o en portales de intervención ciudadana, donde existen secciones en las que se generan miles de comentarios que en escasas ocasiones se podrán considerar información relevante.
«Si la etiqueta canonical es correcta, no hay razones para temer una penalización en casos de duplicidad»
Contenido duplicado
El contenido duplicado se da en los casos en los que existe más de una URL apuntando a la misma página y ambas se han indexado. Es un buen motivo para que Google detecte anomalías que a la postre podrían desembocar en una penalización. Si se da este caso, es porque probablemente no estemos dando un uso correcto a la etiqueta de enlace rel=»canonical», la cual sirve para indicar cuál es la página canónica en cada caso y cuya presencia será una señal directa para que el buscador entienda cuál es la que debe indexar y cuál o cuáles no. Si la etiqueta canonical es correcta, no hay razones para temer una penalización en casos de duplicidad, no obstante, conviene asegurarse de que el enlazado interno se corresponde con ella, es decir, que la mayoría de enlaces apuntan hacia la URL canónica. Si no fuera así, Google podría llegar a indexar la URL no canónica, incluso las dos.
La duplicidad de contenido podría darse, por ejemplo, en una página accesible desde las siguientes URLs, en las cuales el contenido es invariable:
dominio.com/pagina
dominio.com/pagina/
dominio.com/pagina.html
dominio.com/pagina?p=1
dominio.com/pagina?p=2
dominio.com/pagina?p=3
En esta situación, habría que determinar cuál es la URL que deseamos indexar (canónica) y más tarde, en las cabeceras de todas estas páginas, incluida la canónica, insertar la canonical apuntando a ella. Si decidimos que la canónica es dominio.com/pagina, la etiqueta debería ser:
<link rel=”canonical” href=”http://www.dominio.com/pagina” />
Un recurso útil para buscar indicios de duplicidad de contenido es la herramienta de Mejoras de HTML de Google Search Console, a partir de la cual podremos investigar el contenido y las etiquetas canonical en páginas cuyo título se repite. Basándonos en estas repeticiones, empezaremos a examinar el contenido de todas las páginas en busca de duplicidad.
Entonces, ¿la canonical es capaz de controlar el mundo? Desde luego que no. Si una URL no canónica posee gran cantidad de enlaces internos, probablemente Google tenga tan en cuenta este hecho que la termine indexando por delante de la canónica aún poseyendo la etiqueta.
Enlazado interno
Es tan importante crear secciones con contenido de calidad como saber enlazarlas entre sí. Aquí entra en juego el concepto de experiencia de navegación del usuario unida a su estado o nivel de decisión. Si, por ejemplo, yo estoy interesado en comprar un móvil concreto y me estoy informando a través de un artículo sobre las características del mismo, probablemente clicaré en un enlace que me lleva a otra página donde se muestran todos los accesorios que puedo utilizar con él, puesto que este contenido me permite avanzar en mi decisión. En cambio, no haré clic en un enlace que me lleva a ver una página donde encontraré una comparativa entre dos tablets, ya que ésta no me va a aportar nada positivo en mi camino a decidirme a comprar el móvil que quiero.
«Es tan importante crear secciones con contenido de calidad como saber enlazarlas entre sí»
Si deseas profundizar en estrategias de enlazado interno para mejorar el posicionamiento, no te pierdas nuestro post sobre arquitectura de la información y SEO en tiendas online.
Enlaces no rastreables
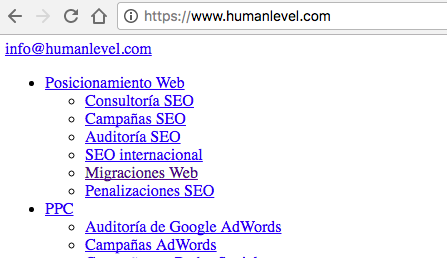
Se debe evitar a toda costa la inclusión de enlaces de tipo JavaScript hacia secciones con contenido relevante, puesto que Google no es capaz de rastrearlos correctamente y podría perderse apartados de vuestra web importantes para la indexación. Un recomendación directa en este caso es construir los enlaces en HTML para que puedan ser seguidos por las arañas. Para comprobar a ciencia cierta si los enlaces son o no rastreables, debéis desactivar las funciones JavaScript en vuestro navegador y más tarde intentar navegar por ellos. Si responden, serán rastreables y si no, con casi total seguridad estarán programados mediante JavaScript. Si además desactiváis el CSS, para confirmar al 100% si son rastreables debéis fijaros en si tienen aspecto de enlace típico de HTML, en color azul y subrayado, tal y como aparecen en la imagen siguiente:
Herramientas para el estudio de la indexación
Google Search Console
Si hay una herramienta que debamos destacar en cuanto al análisis de la indexación de nuestra web, esa es Google Search Console, ya que es la que recoge de primera mano información de gran importancia sobre el sitio. Haciendo uso de ella, no solo accederemos a datos sobre el número de páginas indexadas, los errores de rastreo que se están produciendo (aunque no los muestra actualizados al día), el tiempo de descarga de las páginas, el número de páginas rastreadas al día, la saturación (páginas indexadas/páginas enviadas) de los sitemaps o la distribución de enlaces internos, sino que nos permite realizar pruebas de funcionamiento y nos muestra avisos cruciales para evitar penalizaciones. Además, ofrece un análisis de búsqueda que incluye un informe completo sobre las consultas a través de las cuales han accedido los usuarios al sitio, las páginas a las que han accedido, los dispositivos utilizados, las veces que ha aparecido la web en los resultados, el CTR y la posición.
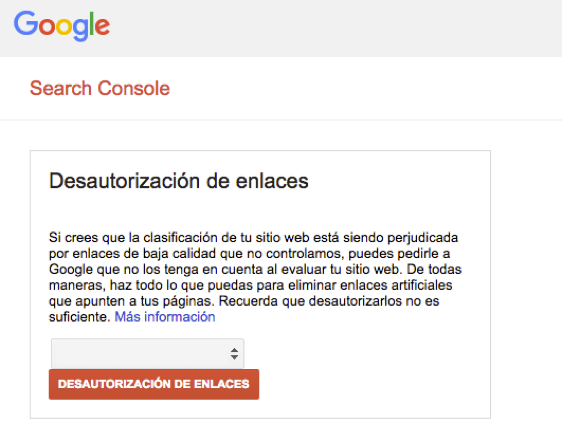
Es posible, también a través de Google Search Console, configurar los parámetros de las URLs para indicar a Google la finalidad de cada uno. Incorpora una herramienta muy útil para comprobar al instante si el archivo robots.txt está bloqueando un directorio concreto y una de mis funciones favoritas: la herramienta Disavow. Con esta funcionalidad podemos desautorizar enlaces entrantes que consideramos pueden estar perjudicando a nuestro sitio.
Search Console también nos da la posibilidad de conocer los problemas de usabilidad móvil que pueda estar presentando la web y que puedan estar impidiendo una navegación óptima de los usuarios de dispositivos móviles, como texto demasiado pequeño o enlaces excesivamente próximos entre sí. Esta herramienta se encuentra dentro de la opción Tráfico de búsqueda -> Usabilidad móvil.
Por último, destacar la opción de visualizar el contenido de la web tal y como Google lo hace, mediante la opción Rastreo -> Explorar como Google. Es posible probar cualquier página del sitio y observar el resultado tanto para escritorio como para móvil. A partir de aquí, veremos si estamos bloqueando recursos que impidan a Google rastrear correctamente nuestra web y tomar medidas al respecto.
Screaming Frog
Es capaz de rastrear un sitio completo y de extraer una cantidad muy valiosa de información sobre el mismo en tiempo real, como por ejemplo códigos de respuesta, enlazado interno y externo con su anchor correspondientes, títulos y meta descripciones de las páginas, encabezados H1 y H2, directivas (caononical, next/prev, index/noindex), imágenes con su alt y su tamaño, además de múltiples filtros y posibilidades de exportación a hojas de Excel que harán que cuando la probéis, no podáis vivir sin ella. Además, recientemente han actualizado a su versión 8.1 y han llevado a cabo un visible cambio de aspecto, así que si no lo habéis probado todavía, esta es una buena oportunidad para hacerlo.
Screaming Frog es un recurso que os será de utilidad prácticamente en el 100% de los proyectos gracias a la gran cantidad de datos que es capaz de obtener y a su capacidad de exportación de sus tablas a hoja de cálculo. Es veloz a la hora de rastrear un sitio web e incluye múltiples opciones para acotar los rastreos, centrándose exactamente en lo que estáis buscado.
Si consideráis que vuestra web no está indexando todo lo que podría o por el contrario, vuestra saturación es muy alta, quizá debáis considerar dar un repaso detenidamente los puntos que expongo en este artículo. ¿Cuántos de vosotros/as pensáis que vuestra indexación es perfecta? ¡Contadme vuestras experiencias!



Hola Rubén, muy buen artículo.
Yo tengo un sitio de anuncios y la verdad es que Google no me indexa ni el 25% de los a nuncios ni de categorías por lo que pierdo una barbaridad de tráfico.
Google se está volviendo muy delicadito.
Un saludo.
Hola Rubén, un placer leerte. Gracias por tu artículo, excelentemente explicado y muy entendedor.
😉