Written by Rubén Martínez
Índice
For a website to appear in the search results of a Google user, the prerequisite is that the pages of that site are included in the search engine’s index. Explained in a very general way, the process by which Google is able to display results after a query, is divided into three main phases:
- Crawling: Google finds new pages and adds them to its index.
- Indexing: reads the site and processes its content.
- Publication: after the query, a process of selection of the most appropriate results is initiated, where more than 200 factors come into play to determine the relevance of each one, so that it is possible to establish a classification or ranking.
It is in the first two phases that the web manager has the possibility to intervene in search of a direct benefit. This is why, if we want our site to be found by those who perform related searches, the first step we must take is to make sure that it is properly crawlable and indexable.
Provide relevant and indexable content
It is as obvious as it is important that a website contains relevant information, and by relevant I mean clear, specific and capable of solving problems and satisfying the user’s needs. But this is not all, since there are some technical requirements to be met beforehand so that, in addition to the users, Google likes the website.
An excellent way (maybe the best?) for the search engine to take good note of our website and decide to show it in many occasions and in good positions, is to try to be a point of reference within the sector, so that A clear recommendation in this regard is to enrich the content of the site as much as possible by providing valuable information for the user.The URLs, titles, meta descriptions, texts, headings and images of each page form cores of relevant content oriented to specific topics and, through a distribution of internal links, we can transfer to our convenience the popularity among the linked pages. This pattern will hold true regardless of whether it is a travel blog or an antiques e-commerce.
But what happens if we start creating and publishing texts without control or structure? We will surely incur in duplicity of content, in pages with little relevant content, in contradictions between 301 redirects and canonical tags, in a poorly designed information architecture and in internal linking without a clear focus. As we have previously mentioned in other articles, in order to carry out all these steps properly, a keyword research should be carried out beforehand, which will show us the way to follow based on the most important terms of the sector in which we work.
It should be added that not all the content of a site will necessarily be indexable. That is why we have different resources that will help us to indicate to Google what we want and what we do not want it to include in its index.
Which content not to index
We must keep in mind at all times that the saturation or percentage of indexed pages of our website must respond to a coherence with the relevant content we have on the site. For this, there are different resources that will help us to interpose blockades either punctually or definitively to pages and even complete sections of the web. The tool par excellence for this type of process is the robots.txt file, especially if it is necessary to restrict the crawling of a large number of pages or an entire subdirectory. It is a matter of finding a balance, especially if we are talking about a large portal, in which we do not waste the spiders’ resources and allow them to focus on what is really important.
It is very common that, for example in WordPress, we do not want the subdirectory /wp-admin, corresponding to the administrator area, or the folders where the plugins and themes are hosted to be indexed, for which it will be necessary to include the following lines in the robots.txt file:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
It does not mean that everything we do not include in the robots.txt file will be indexed, however, if crawlers find links to these sections, they are very likely to be included in the index if we have not taken precautions to block these pages.
rel=”nofollow” attribute
The rel attribute with nofollow value is a feature that we must know how to take advantage of when creating the internal link network. You must include a nofollow to all those links whose target page you do not want to be crawled and therefore indexed by the search engine, such as links to the private area. Not including the rel attribute in a link will cause it to be considered as a follow and will therefore be followed by robots.
Thin content or insignificant content
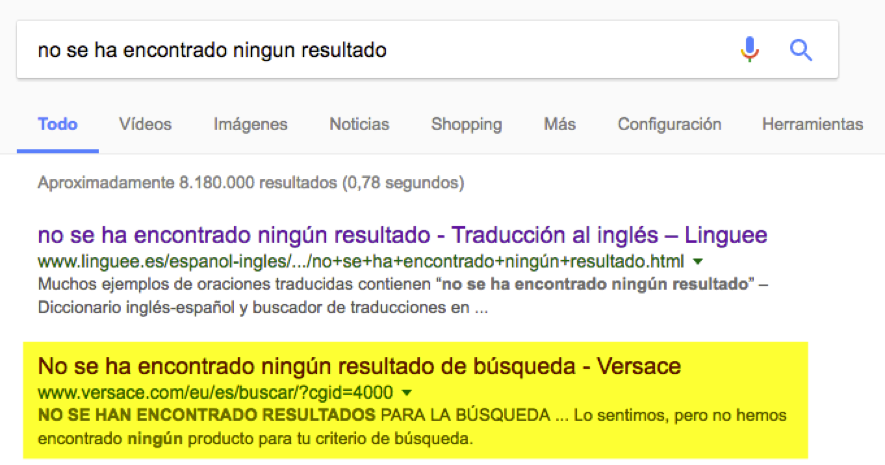
The pages whose indexation we want to avoid are those that do not show relevant content to the user. For example, “no results found” pages like the one we see in the image below on the Versace website:
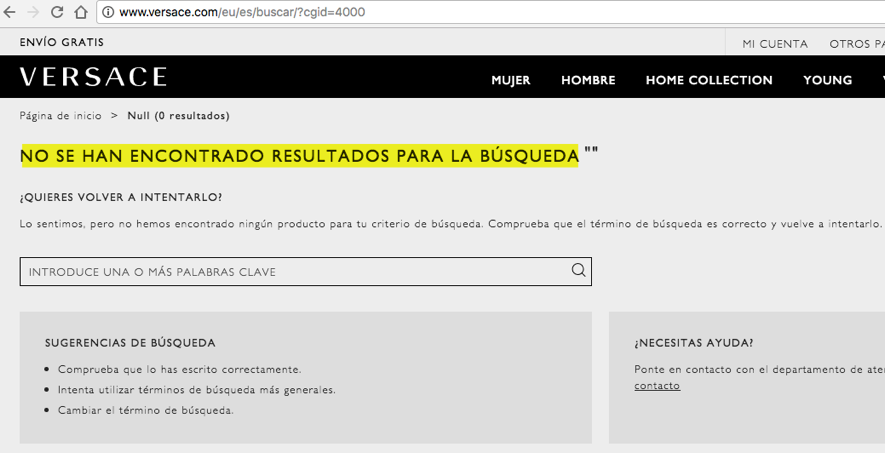
Clicking on the second result takes you to a page with no content:
It is true that it may seem absurd to perform a search of this type, however, this is a clear example that it does not make sense for Google to spend resources to read and store pages without any value for the user, since the crawl limit is a parameter that is set internally and if the spiders spend time reading and storing non-relevant sections, it could reduce the crawl frequency by considering the site of low quality. In cases where a large number of such pages are indexed, further investigation is required to detect the root cause of their generation and to block them.
Other cases may occur, for example, in banking portals, where certain sections must remain unindexed for security reasons, or in citizen intervention portals, where there are sections in which thousands of comments are generated that can rarely be considered relevant information.
“If the canonical tag is correct, there is no reason to fear a penalty in cases of duplicity.”
Duplicate content
Duplicate content occurs in cases where there is more than one URL pointing to the same page and both have been indexed. This is a good reason for Google to detect anomalies that could eventually lead to a penalty. If this is the case, it is probably because we are not using the rel=”canonical” link tag correctly. serves to indicate which page is the canonical page in each case and whose presence will be a direct signal to the search engine understands which one(s) to index and which one(s) not to index. If the canonical tag is correct, there is no reason to fear a penalty in cases of duplicity, however, you should make sure that the internal linking corresponds to it, i.e. that the majority of links point to the canonical URL. Otherwise, Google may index the non-canonical URL, or even both.
Duplicity of content could occur, for example, on a page accessible from the following URLs, where the content is unchanged:
domain.com/page
domain.com/page/
domain.com/page.html
domain.com/page?p=1
domain.com/page?p=2
domain.com/page?p=3
In this situation, we would have to determine which URL we want to index (canonical) and later, in the headers of all these pages, including the canonical one, insert the canonical pointing to it. If we decide that the canonical is domain.com/pagina, the tag should be:
<link rel=”canonical” href=“http://www.dominio.com/pagina”/>
A useful resource for looking for signs of duplicate content is the HTML Enhancements tool in Google Search Console, from which we can investigate content and canonical tags on pages whose title is repeated. Based on these repetitions, we will start examining the content of all pages for duplicity.
So, is canonical able to control the world? Certainly not. If a non-canonical URL has a large number of internal links, Google will probably take this fact into account so much that it will end up indexing it ahead of the canonical one even if it has the tag.
Internal linking
It is as important to create sections with quality content as it is to know how to link them together. This is where the concept of user navigation experience coupled with the user’s state or decision level comes into play. If, for example, I am interested in buying a particular cell phone and I am getting information through an article about its features, I will probably click on a link that takes me to another page where all the accessories that I can use with it are shown, since this content allows me to advance in my decision. On the other hand, I will not click on a link that takes me to a page where I will find a comparison between two tablets, as this will not bring me anything positive on my way to deciding to buy the cell phone I want.
“It is as important to create sections with quality content as it is to know how to link them together.”
If you want to learn more about internal linking strategies to improve positioning, don’t miss our post about information architecture and SEO in online stores.
Untraceable links
JavaScript links to sections with relevant content should be avoided at all costs, since Google is not able to crawl them correctly and could miss sections of your website that are important for indexing. A straightforward recommendation in this case is to build the links in HTML so that they can be followed by spiders. To check for sure if the links are traceable or not, you should deactivate the JavaScript functions in your browser and then try to navigate through them. If they respond, they will be traceable and if not, they will almost certainly be programmed via JavaScript. If you also deactivate the CSS, to confirm 100% if they are crawlable you should check if they look like a typical HTML link, in blue color and underlined, as shown in the following image:
Tools for the study of indexing
Google Search Console
If there is a tool that we should highlight in terms of the analysis of the indexing of our website, that is Google Search Console, since it is the one that collects first-hand information of great importance about the site. By making use of it, we will not only have access to data about the number of pages indexed, the crawl errors that are occurring (although it does not show them up to date), page download time, number of pages crawled per day, saturation (pages indexed/pages submitted) of the sitemaps or the distribution of internal linksbut allows us to perform tests and shows us crucial warnings to avoid penalties.. In addition, it offers a search analysis that includes a complete report on the queries through which users have accessed the site, the pages they have accessed, the devices used, the times the website has appeared in the results, the CTR and the position.
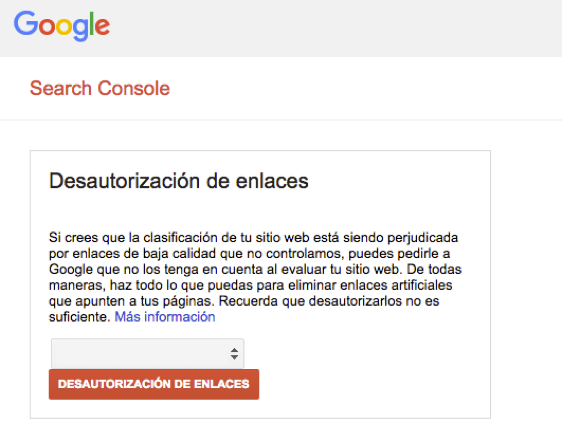
It is also possible, through Google Search Console, to configure the parameters of the URLs to indicate to Google the purpose of each one. It incorporates a very useful tool to check instantly if the robots.txt file is blocking a particular directory and one of my favorite features: the Disavow tool. With this functionality we can disavow inbound links that we consider may be damaging to our site.
Search Console also gives us the possibility of knowing the mobile usability problems that may be presenting the web and that may be preventing an optimal navigation of users of mobile devices, such as too small text or links too close together. This tool can be found under the Search Traffic option -> Mobile Usability.
Finally, it is worth mentioning the option to visualize the content of the web as Google does, through the option Crawl -> Explore as Google. It is possible to test any page of the site and observe the result for both desktop and mobile. From here, we will see if we are blocking resources that prevent Google from correctly crawling our website and take action.
Screaming Frog
It is able to crawl a complete site and extract a very valuable amount of information about it in real time, such as response codes, internal and external links with their corresponding anchor, page titles and meta descriptions, H1 and H2 headers, directives (caonononical, next/prev, index/noindex), images with their alt and size, as well as multiple filters and export possibilities to Excel sheets that will make you can’t live without it once you try it. In addition, they have recently updated to version 8.1 and have made a visible change in appearance, so if you haven’t tried it yet, this is a good opportunity to do so.
Screaming Frog is a resource that will be useful in almost 100% of the projects thanks to the large amount of data it is able to obtain and its ability to export its tables to a spreadsheet. It is fast when crawling a website and includes multiple options to narrow down the crawls, focusing on exactly what you are looking for.
If you consider that your website is not indexing as much as it could or, on the contrary, your saturation is very high, maybe you should consider taking a close look at the points I expose in this article. How many of you think your indexing is perfect? Tell me about your experiences!