

Written by Jose Vicente
Index
To perform technical audits we usually resort to crawlers or SEO tools that extract the tags involved in positioning such as title, meta tags, title hierarchy tags, etc. Generally, these tools such as Screaming Frog or Ryte extract a large number of these factors, but there are many types of sites and each of them has its peculiarities.
It is highly recommended to choose a tool that allows us to configure customized variables that will help us to more accurately evaluate each project. This configuration is usually done in different ways, the most common is to use regular expressions and XPath selectors that will help us to identify what we want to extract in each page.
What are regular expressions and XPath
Regular expressions allow us to make searches that meet a certain pattern within texts, which in this case will be HTML. Although it depends on the program we use, most of them comply with the standard specification that we can consult in many sites such as:
Since in many occasions we will not be interested in simply searching for certain character strings within a text, but in capturing the content or counting those that meet a certain pattern, we will have to resort to the use of regular expressions and XPath selectors.
It is highly recommended to know their syntax and understand how they work, as we can use them in many tools and they will save us a lot of work. An example of this is the use in Google Analytics that we have already seen in this article.
XPath
follows a similar idea to regular expressions but its operation is different since it can only be applied to XML structures, which in this case is the case of HTML. Therefore its limitation is that we cannot apply it to plain text as in the case of regular expressions, but you will see that for certain uses it is more accurate because we can select certain elements unambiguously.
As in the case of regular expressions, we can consult a lot of documentation on how these selectors are used:
But let’s see how they work with an example.
Obtaining the canonical of each page
Although this is something that we can get with all known SEO crawlers, but we have encountered on many occasions with errors in certain configurations, for example, in Screaming Frog when a URL indicated is relative to the protocol it rewrites it depending on the protocol with which it has accessed. If we are reviewing the canonical implementation and want to check what particular literal the programmers have set up on each page of the site to detect errors, Screaming Frog’s default functionality will not work for us.
As you know the rel canonical link tag has the following syntax:
<link rel=“canonical” href=“https://www.ejemplo.com/" />
Then simply using the regular expression <link rel=”canonical” href=”(.*)” /> should locate that pattern within the HTML and return the literal that appears within the quotes of the href attribute. But what happens if for example the rel and href attributes are exchanged or if some additional attribute is added? We should take into account all possible variations in the regular expression we set up.
This should be solved by obtaining the value via XPath since it will simply be a reference to the href attribute of the link element whose rel attribute is equal to canonical. The selector in this case would be the literal //link[@rel=”canonical”]/@href , and so we get the value of the href attribute of the link elements whose rel is canonical.
This way we do not care about the order in which the rel and href attributes appear in this case since the engine will look for the link element that meets the condition. Then, although we could surely solve all the different options with regular expressions, in this case it would be safer to do it with XPath to cover all the possible options.
Obtaining Google Analytics ID
A very different case would be if we wanted for example to capture the Analytics tracking code present on every page of the site. In this case, since the code must be inside a script element, it is not possible to select the specific XPath of the UA code. Therefore, we would have to search for it within the text with a regular expression such as ua-[0-9]{6}-[0-9] in which we tell it to look for a text beginning with ua- and followed by 6 numerical digits, another hyphen and finally another digit.
Examples of custom variable extraction with Ryte
To test the extraction using regular expressions and Xpath we are going to use Ryte as an example, although it is something we can do with other tools applying the same logic. Ryte already manages a large number of standard indicators directly related to SEO, but as we have already said, it is very helpful to be able to create our own indicators since each project has its own peculiarities.
In this case Ryte has two functionalities to create customized Snippets:
- Custom count: allows us to count the occurrences of the pattern entered on each page analyzed.
- Custom fields: allows us to collect in a custom variable the text or html that meets the indicated pattern.
Number of category listing items
In the current times in SEO this is a very interesting indicator as it allows us to detect listings that show a small number of elements. These pages are often identified by Google as thin content and can jeopardize the positioning of our site.
With Ryte we can do this by setting up a‘Custom Count’ of the tag type contained in each of the listed items. For example, in a WordPress tag, the articles listed in the tag <article> are usually formatted. Then we just have to select the Custom Snippets option in Ryte and within it configure a ‘Custom Count’ as we see below.
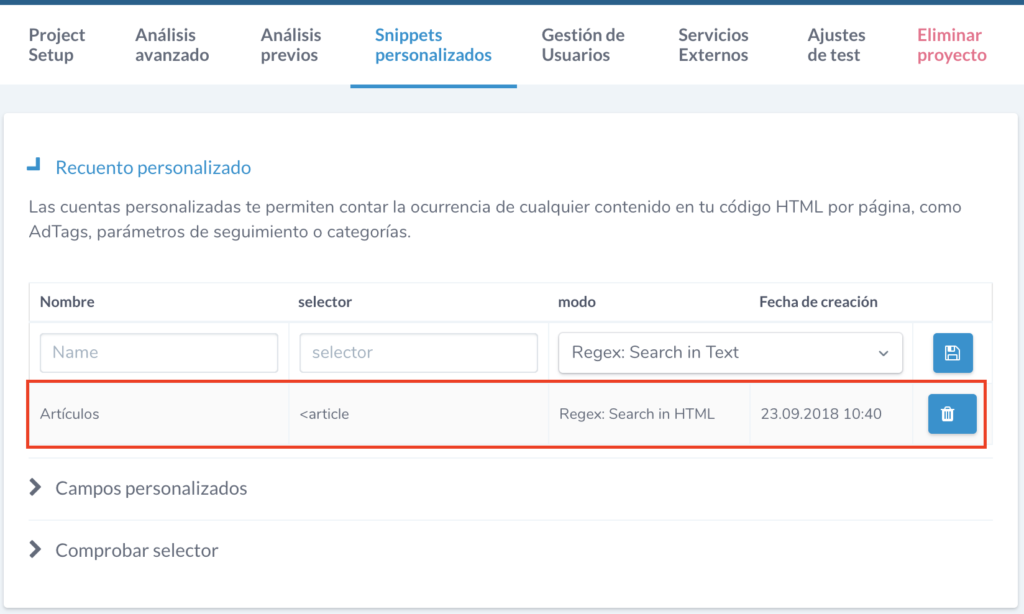
Once this is configured, the next time the site is crawled we will get a custom variable called Articles in which the number of <article> tags appearing on the page will be counted. To access it we go to the menu option Website Success > Content > My custom counts and within this option we will find our Articles variable that will show the following graph.
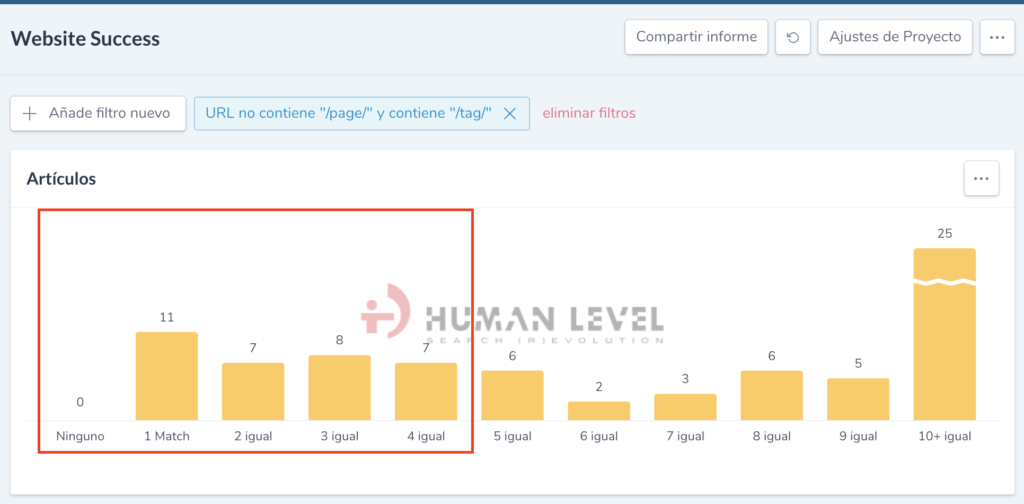
This report shows us the number of pages where a certain number of items have been found, for example we can see that there would be 11 tags that would list a single item, 7 tags that would list only 2 items and so on. To further refine the analysis we have applied a filter so that we can see tag data excluding pagination.
It would therefore be advisable to analyze the tags with the lowest number of related items, specifically for each case we will review:
- If they are necessary and we can increase the amount of content or we should deindex them.
- If they are dispensable and we can eliminate them.
As Ryte allows us to customize the reports by adding Google Analytics columns, it would be interesting to contrast these values with the number of sessions or page views. This will give us one more piece of information to support our decision or to analyze whether there is a direct correlation between the number of items listed and their performance.
Number of comments on the product sheets or posts
Comments are a valuable source of additional content for our online store product sheets or blog articles. In addition to the amount of content, your text contains a long tail that provides the users’ own language and greater positioning alternatives.
In our example site, the comments are laid out inside a div element whose id is equal to comments and inside this element each comment is laid out inside an article tag. So let’s set up a count of the article tags inside this div with the following XPath selector //div[@id=’comments’]//article .
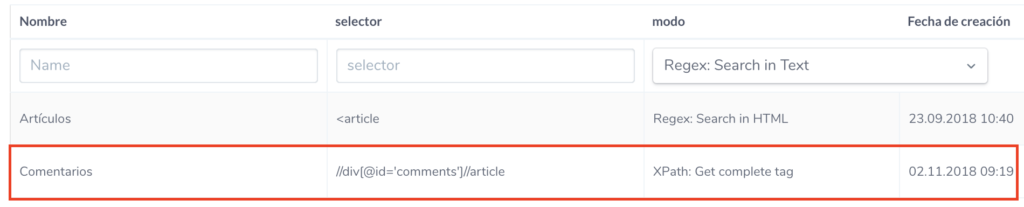
This way is more accurate than the previous Article count configuration since it counts the article tags inside the each comment on each page. In the previous case, we simply check how many times the literal <article appears in all the HTML of the page without taking into account in which part of the page it appears.
More metrics that can be interesting for SEO
We have seen some examples configured in a specific case that can help you to apply it in your specific case. These would be some additional metrics ideas that would be worth looking at.
- Length of item descriptions, categories or item content.
- Number of product images or images inserted in the content of the articles.
- Author of the articles.
But the indicators can be as many as there are different sites and in any case these customized variables can help us to evaluate our website and establish comparisons with our competitors.
How to test the configuration before tracing with Ryte
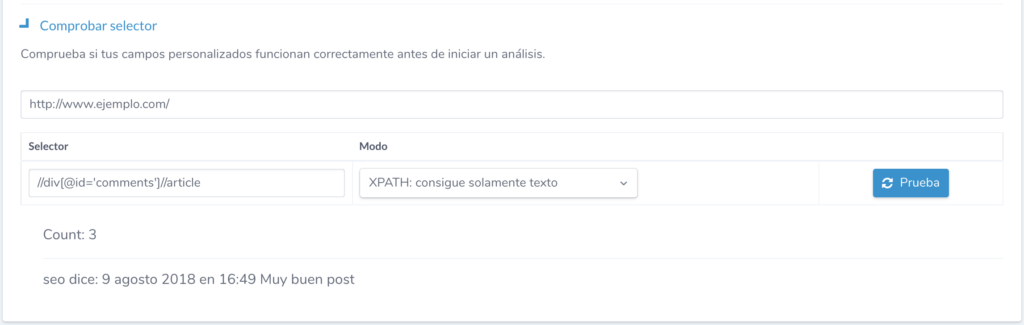
To avoid having to wait for Ryte to crawl the entire site , we can pre-check the selectors or regular expressions with the Check Selector feature in the Custom Snippets section. We only have to insert a test URL, the configured selector and the way it should be interpreted to obtain the number of elements that meet the pattern and an example of the code containing the first one found.
Although there are hundreds of SEO factors applicable to all types of websites, there are characteristics specific to each website that we will not be able to evaluate with the standard configuration of SEO tools. It is therefore important to have one that allows them to be implemented and to have a thorough understanding of their possibilities in order to correctly analyze their performance and possibilities for improving visibility.



