

Written by Fernando Maciá
Index
 The term Information Architecture (IA) is the term used to describe the structure of a system: the way in which information is grouped, the ways in which the contents can be navigated and the terminology used within the system.
The term Information Architecture (IA) is the term used to describe the structure of a system: the way in which information is grouped, the ways in which the contents can be navigated and the terminology used within the system.
A well-designed information architecture allows users to employ a system with the confidence that they will be able to easily find the information they are looking for. Most people only become aware of the existence of an information architecture when it is poorly implemented and represents an obstacle to achieving their objectives.
Origin of the concept
The term “information architecture” was coined by Richard Saul Wurman in 1975. Wurman’s initial definition of information architecture was“organizing patterns into data, turning the complex into the simple“. The term was rarely used until 1996, when two librarians –Peter Morville & Louis Rosenfeld– rescued it to define the work they were doing in structuring large websites and intranets. In Information Architecture for the World Wide Web: Designing Large-Scale Websites they defined information architecture as:
- The combination of organization, labeling and navigation schemes within an information system.
- The structural design of an information space to facilitate task completion and intuitive access to content.
- The art and science of structuring and classifying websites and intranets to help users find and manage information.
- An emerging discipline and common practice focused on applying the principles of design and architecture to a digital environment.
Information architecture and usability
Today, these general concepts relating to information architecture are embodied in concrete terms in the first task to be undertaken in the creation of a new website: the definition of the site’s structure. A well-organized website is one that allows its users to find what they need easily and intuitively. In general, the easier it is for users to navigate the website, the longer they will stay on the site and have the opportunity to reach a greater proportion of content, as well as providing them with a satisfactory user experience that will motivate them to return. A well-structured website also facilitates the logical growth of the site by adding new content.

Likewise, the shorter the journey a user has to make from the moment they arrive at the website until they achieve the objective for which they arrived –whether buying, viewing information, downloading an instruction manual or subscribing to a newsletter– the better the conversion rate. It is generally accepted that the fewer clicks involved in a given conversion funnel, the better the ratio. One of the most common processes of optimizing the usability of a purchase process is precisely to reduce the number of clicks that the user will have to make to complete the purchase.
Information architecture in SEO
In SEO, the structure of a website has equally important repercussions on the ease with which search engines will be able to crawl all its content and calculate the relative importance of each of them with respect to the rest, i.e. on its indexability and relevance, particularly in three aspects:
- Frequency: in general, the more frequently a website updates its content, the more frequently it will be visited by search engine spiders to keep the index information up to date. Therefore, including news sections, Twitter updates, product carousels or sections such as “Most searched”, “Most read” or “Latest comments” will encourage search engines to crawl our website more frequently.
- Breadth: the aim is to ensure that search engines index the widest possible proportion of content within the same level of content. For example, in a listing of products from the same family, the products linked first will be more likely to be indexed than those that appeared last in the listing. When listings are so large that they are divided into pages (paginated) this is especially serious, as experience shows that search engines do not index successive pages of results listings well. But at the same time we know that an excessive number of outbound links on a single page is not good. So we will have to find the best compromise between number of products or results listed on the same page (to avoid pagination) and total number of outbound links on that page.
- Depth: it is about getting search engines to index content located several clicks away from the home page. These contents occupy deeper levels in the Web’s information architecture and are generally focused on long-tail positioning. In order to keep as much of this type of content indexed as possible, it is advisable to include sections with links to related content so that as much content as possible is linked to from relevant and popular pages. These related contents also increase the average number of page views per session, as well as the possibility of upselling (increase the total value of the order as when, when renting a car, we are offered a better model than the one initially selected for a marginal added cost) and cross selling (increase the number of products in the order by encouraging the user to include accessories and complements).
Although we can generate sitemap files to facilitate the process of discovering new pages of our Web to search engines, we must emphasize that the sitemap file should be considered a complement, not a substitute, for a logical information architecture, navigable and accessible to search engines through a crawlable navigation menu.
If you want to go deeper, check out our post on how to orient the information architecture to the SEO of your website.
Types of information architecture for a website
Websites are built based on the definition of a certain structure. This architecture is the basis of its navigation scheme and recreates in the users a mental model that reflects the way in which the information and the different contents that make up the website have been organized. Basically, there are three types of structure that we can use to build a new website: the sequential model, the hierarchical model and the network model. Each of these structures will have an important influence on the way in which visitors will navigate through the contents of our Web, but they will also have a different effect on how search engine robots calculate the relative importance of a piece of content with respect to the total of the Web.
The sequential model
The simplest way to order information is to organize it in sequence. The order of the sequence can be chronological, with the contents grouped according to a time criterion and ordered according to an evolution in time. It can also be a logical order in which the topics covered progress from the general to the more specific. Or in alphabetical order, as we find concepts arranged in dictionaries and encyclopedias. The sequential model is appropriate in training websites, where the user is led through a series of consecutive lessons along a linear navigation scheme.
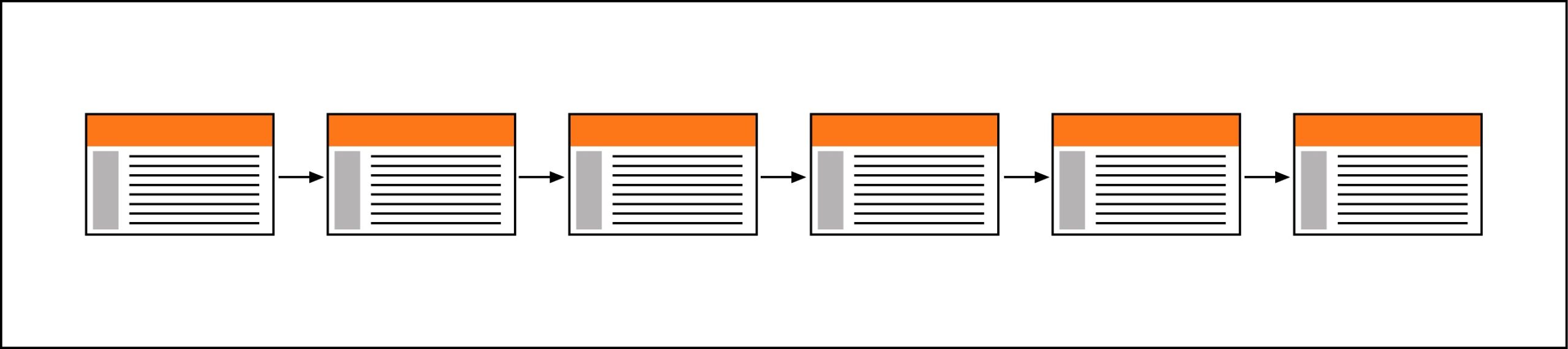
In the sequential model, each page has an outbound link to the next page. In reality, the effect from the search engines’ point of view, is to be delving into a new level of content depth with each new page view as each page is one click further away from the home page. Based on the principle that the entrance page to the portal is usually the one with the highest level of popularity, it is normal in this type of structure that this level decreases as we move along the pages that make up the sequence. In this sense, Google will consider more relevant the first pages of the sequence, that is, those closest to the home page of the Web.
The hierarchical model
Hierarchical structures are the best way to organize large volumes of complex information. Websites are often organized around a main entry page, from which the different sections develop in underlying levels that progress from the most generic to the most specific, so the hierarchical schema model is particularly well suited to the organization of a website. Hierarchical diagrams are very common in the work environment so most users find this model very easy to understand. Likewise, the organization of the contents in a hierarchical scheme requires a very analytical approach where a priori the different hierarchical levels of each material must be identified.
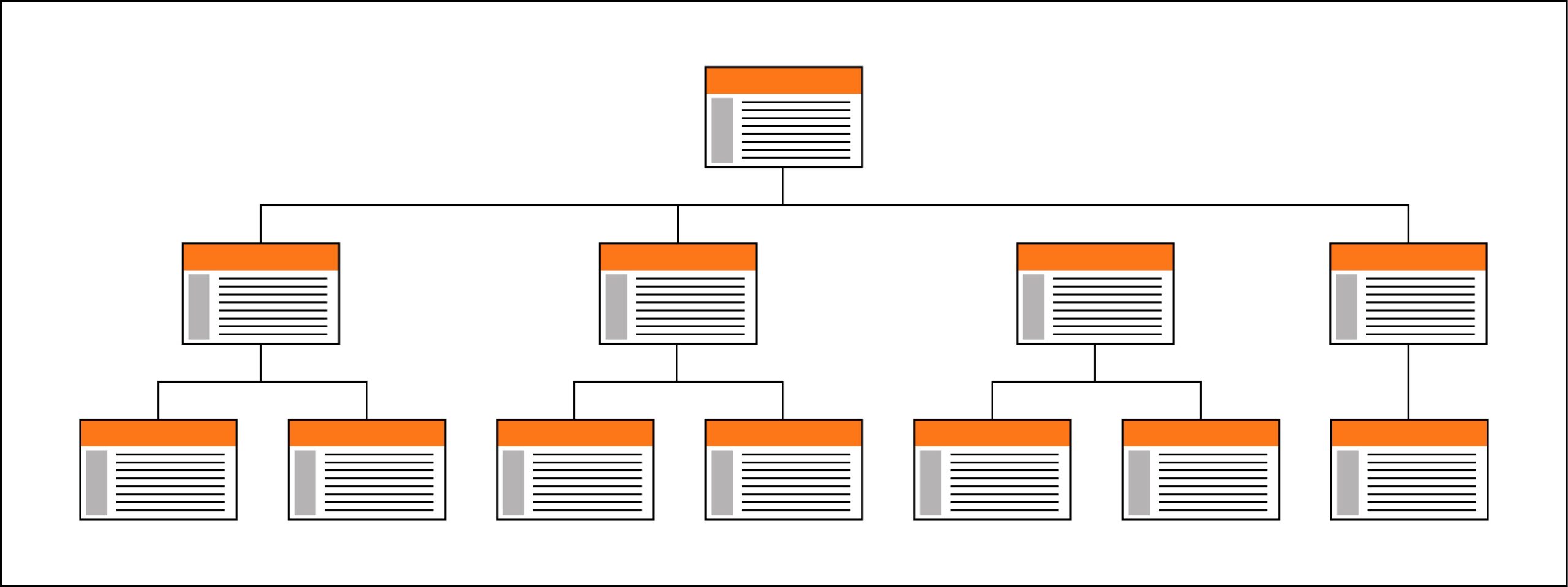
The hierarchical web model also favors the main page to receive incoming links from the rest of the webpages. This results in the home page benefiting from the greater number of external links that the Web receives from other portals, as well as from the greater number of internal links that it receives from all of its contents. The practical result will be that the most popular page will be the home page, followed in importance by the section header pages (second level of depth), the third level pages, etc. In other words, popularity will be maximized on the most important pages of the portal: home page and section header pages. Since these pages are the candidates to compete in the most generic searches -generally, the most competitive ones- achieving the highest possible popularity value in them will improve their chances of ranking in more visible positions.
The network model
Network structures are the most flexible when it comes to organizing information. In this type of structure, the objective is to encourage associative thinking and favor the free flow of ideas, allowing users to pursue their interests according to a single pattern. This model is developed through the inclusion of a dense scheme of links both to the rest of the information available on the website itself and to other external pages. Although the aim of this structure is to exploit to the maximum the Web’s ability to relate content to content, network structures can create a confusing impression on users, as they are very difficult to identify and understand, and their behavior is generally unpredictable.
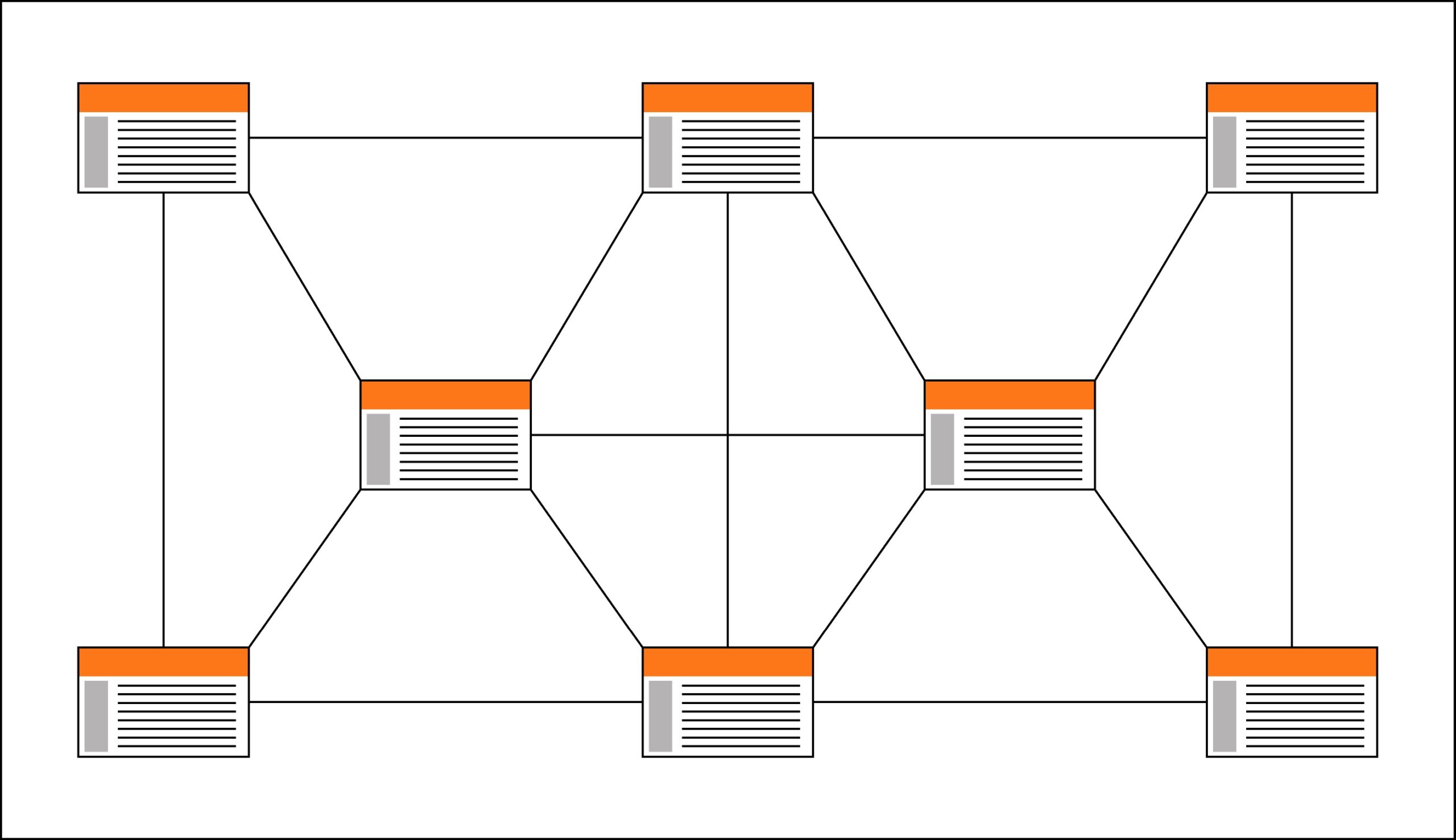
Unlike the hierarchical model, in which popularity is concentrated in a few pages, the network type of organization favors a more balanced distribution of popularity. Indeed, the profusion of transversal links to different levels of content depth, which characterizes the network structure, blurs the preponderance of the home page present in the two previous models: any page is an entrance and exit to the Web, and from any of them we can “jump” to a totally different section of the Web.
Above a certain size, websites tend to share aspects of these three structure models. Except for those sites that rigidly impose a linear exploration along a sequence of pages, it is more common for users to explore the Web in a fairly free way, more similar to the network model. However, this navigation pattern relies on the predictability of the behavior of the Web according to the mental schema that the user creates of its structure. Thus, this free and non-linear exploration of the site will be satisfactory only if it is carried out on a model that is easy for users to identify and anticipate.
Additional references
Presentation by Fernando Maciá on Information Architecture and SEO: the case of 11811
Information architecture and on-page SEO optimization
Information architectures for SEO
User-Centered Web Design: Usability and Information Architecture

