Written by Fernando Maciá
Index
- .cat domains: what are they?
- Objectives of the SEO experiment: What did we really want to demonstrate?
- Conditioning factors: how to maintain the asepsis of the test
- Proposed methodology
- Neutralized relevance factors
- Content deployment
- Indexing phase
- Content deployment – second phase
- Measurement
- Results
- Conclusions
This was the question that Fundació .cat posed to Human Level at the end of 2021. Although on their website they promoted the adoption of this domain extension by Catalan companies arguing that it could be an advantage in the positioning of their websites for searches in Catalan, this claim had no scientific basis and no study or analysis was available to confirm or refute it. And this was exactly what they asked Human Level to do: design and execute an experiment that would provide empirical evidence for or against.
As an SEO, I felt the same way I did when my parents gave me a Quimicefa lab (a Spanish Chemistry Kit for children) for Christmas. We would have a budget to create an aseptic environment where we could design and develop an SEO experiment to try to demonstrate a cause-effect relationship, not a mere correlation, between the use of a .cat domain and a better positioning in search engines. It was going to be complicated, but we were going to have a blast!
Let’s start from the beginning.
.cat domains: what are they?
All .cat domains belong to a category of top level domains called sponsored Top Level Domain (sTLD) and, within these, domains oriented to a specific geographic area: geoTLD. These types of domains are promoted and managed by a sponsoring entity on behalf of a specific community that shares certain ethnic, geographic, professional, technical or any other interests proposed by private agencies or organizations that establish and enforce rules restricting the eligibility of registrants to use this top-level domain.
The Internet Assigned Numbers Authority (IANA) is the authority in charge of maintaining the Internet Domain Name System, managing both sponsored domains (sTLDs) and generic top-level domains (gTLD – generic Top Level Domain) or country code (ccTLD – Country Code Top Level Domain).
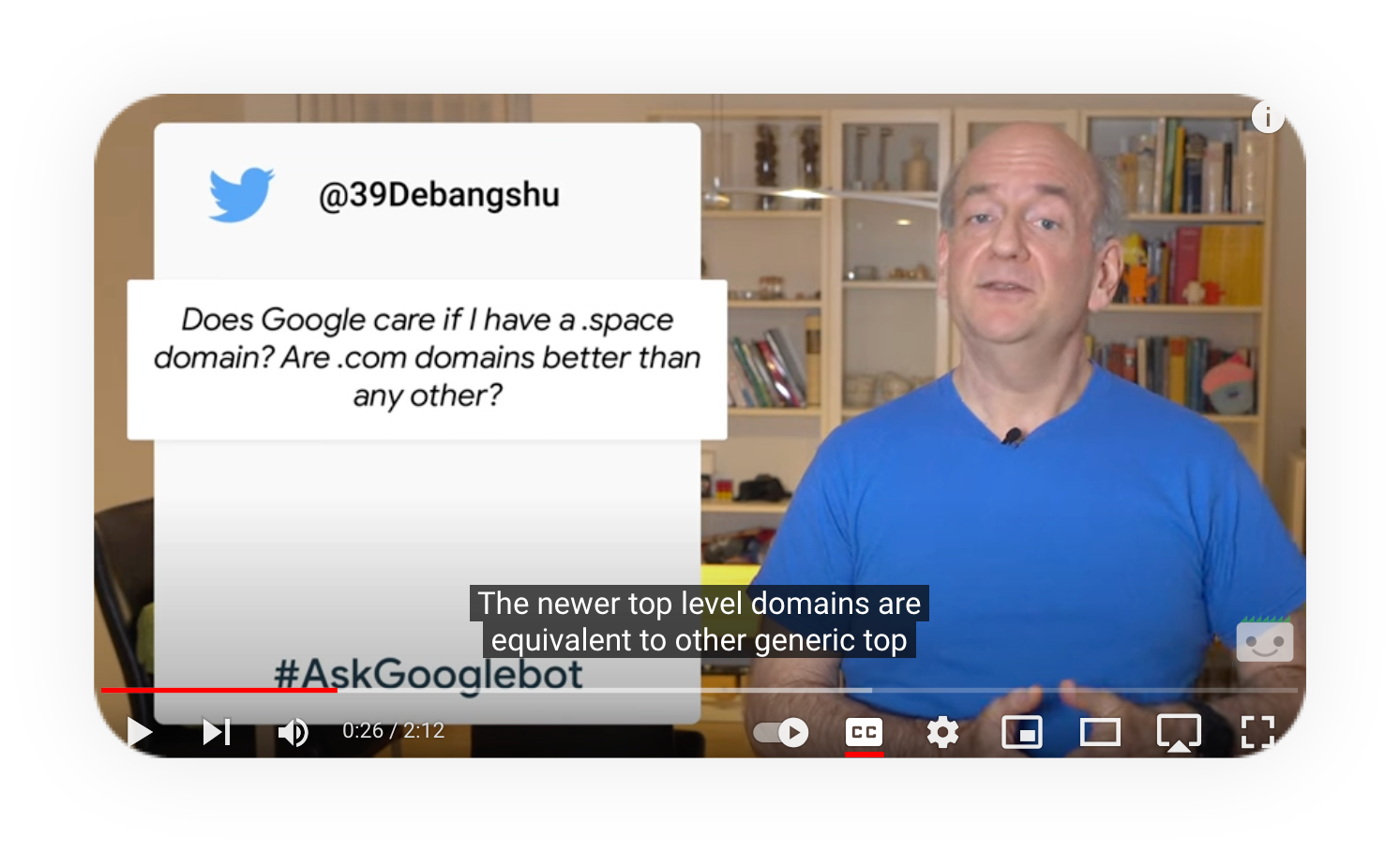
How does Google treat sponsored domains (sTLDs)?
This is a question that has been answered on numerous occasions by official Google spokespeople. In this video, John Mueller states that “we treat all new top-level domains like any other generic top-level domain. There is no additional value in having keywords as a domain extension. There is no additional value in having city or country names as domain extensions. We treat them like any other generic domain, essentially like leica.com. So if you find a domain name that works well for your website, that you want to keep for the long term and corresponds to one of these new extensions, definitely go for it. I think it is perfectly correct”.
So, at least from an official documentation point of view by Google, the experiment should not be able to show any impact, positive or negative, about Google ranking of a content in a .cat domain compared to the same content in a .com or .es domain, for example.
Reality, however, would end up proving the opposite, as we will soon see.
Objectives of the SEO experiment: What did we really want to demonstrate?
In principle, the question posed by the Fundació .cat seemed clear enough. However, it was open to multiple interpretations: Do .cat domains influence positioning? And in which search scenarios?
For example:
- Would they rank better when the search is in Catalan?
- Would they rank better when the search was posed on Google.cat?
- Would they rank better when the crawled content was written in Catalan?
- Would they rank better for searches made from Catalonia?
As well as, obviously, many others and the different combinations of all of them.
Therefore, one of the first points to be established in the study would be to set up the tests from certain search scenarios that would establish these initial conditions and analyze the impact of each of them on the result.
Conditioning factors: how to maintain the asepsis of the test
The most difficult challenge when setting up an SEO experiment that aims to demonstrate a relationship between a certain relevance factor and its influence on the position achieved, lies in the difficulty of establishing and maintaining laboratory conditions that ensure the asepsis of the tests, avoiding the influence of other factors that would contaminate the results and impede the demonstration of the conclusive existence of a cause-and-effect relationship.
Precisely because of this difficulty, most SEO experiments try to identify not a cause-effect relationship, but a correlation. And this difference is fundamental:
- In a cause-effect relationship, we try to conclude that when we perform a certain action, there is always a certain effect directly related to the action performed. For example, whenever it rains, the street gets wet. The street is dry before it starts raining and gets wet due to the water falling as rain, not the other way around.
- In a correlation, we merely observe that when a certain event occurs, it always occurs in the company of another. But we cannot always determine with certainty that one is the direct cause of the other. For example, whenever it rains, most passersby open their umbrellas. An alien might conclude that every time passersby open their umbrellas, it rains, erroneously establishing a cause-effect relationship between the opening of the umbrellas and the fall of rain.
So secondly we had to design an aseptic SEO lab environment where we could isolate and/or neutralize as much as possible the impact on the results of other relevant factors that could affect the measurement of positions. As, for example…
Certain user-related aspects affect the results that each user obtains when searching on Google. Among others, the following are important:
- History of searches, browsing, clicks, etc. recorded by the browser from which the search is made or in our own Google user profile. All of this activity is recorded in the Google My Activity section, as well as in the form of cookies in our browser:
- Language and region settings: configured in our Google Search preferences:
- Geolocation by IP: when we launch a search on Google, the search engine performs a geolocation that it uses to return local results, for example. We can check where it geolocates us in the footer:
All these factors also affect the results presented by Google. If we wanted an aseptic environment, we had to be able to neutralize them so that they would not affect the positions obtained in the measurements.
On-page relevance factors
Comparing under the same conditions how a .com domain, for example, ranks compared to a .cat domain also required neutralizing all on-page relevancy factors that could affect the results.
Factors such as:
- Quality, originality, authority and length of content.
- Semantic factors.
- Language matching: a website in the same language as the one selected as preferred by the user in his browser would favor a better positioning.
- Geolocation of the server: since the proximity of the server to the origin of the search could influence the result.
- CMS used: a different content management system may encourage different content/code ratios, different semantic markup…
- Factors related to user experience (UX) and download speed (WPO): depending on the design, image optimization, prioritization in downloading resources, etc.
Off-page relevance factors
Finally, we also had to match the off-page relevance factors of the domains under comparison.
Factors such as:
- Domain history.
- Number and quality of links.
- Topical domain authority.
- Popularity and social mentions.
- Etc.
Proposed methodology
Domains
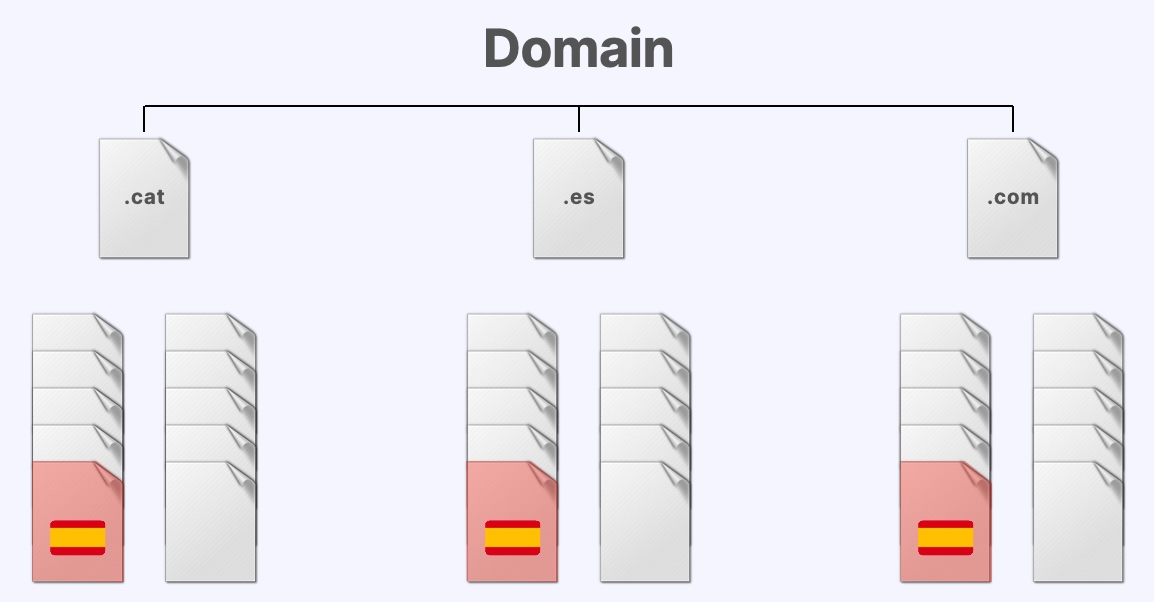
Given the above conditions, we decided that the test should be done on:
- New domains, registered simultaneously, to equalize their seniority.
- Domains without external links, to match their authority and popularity.
- Domains without any initial semantic relevance for their own domain name.
- Domains whose content should use exactly the same server infrastructure, CMS and theme or template to match any aspect related to geolocation or server performance, download speed, etc.
- A number of domains that would give us the possibility of having a sufficiently representative sample to guarantee the validity of the results obtained.
With this in mind, we used stemming tools such as Snowball to check the semantic neutrality of the selected domain names. Basically, it was a matter of finding words that meant nothing in any of the test languages (Spanish, English or Catalan).
After various tests, these were the ten domains selected:
- Abtuniolasti.
- Zirgomaselon.
- Sendueplontu.
- Jolbiatrac.
- Trunipazel.
- Apeledesel.
- Tiriunbeladu.
- Capmanisol.
- Panfalustob.
- Bantevartron.
We then registered the extensions .es, .com and .cat for each of these ten domains, resulting in a total of thirty new simultaneously registered and semantically neutral domains. Obviously, none of them had any history or external link, so they all shared exactly the same (null) popularity/authority.
Server
Each domain was in turn hosted on a Cloudflare CDN server. A CDN or Content Delivery Network basically consists of a server replicated geographically in different datacenters around the world. Thus, requests received by a domain hosted on a CDN are handled by the server closest to the origin of the request. This favors lower response latency and, more importantly for the experiment, neutralizes server geolocation as a relevant factor for positioning.
Content Management System
Finally, we did an identical WordPress CMS installation on each of the domains and using its most basic template.
In this way, we also neutralized any influence derived from the content manager, template or plug-in used, features and geolocation of the server. All domains would use exactly the same technical infrastructure.
Information architecture
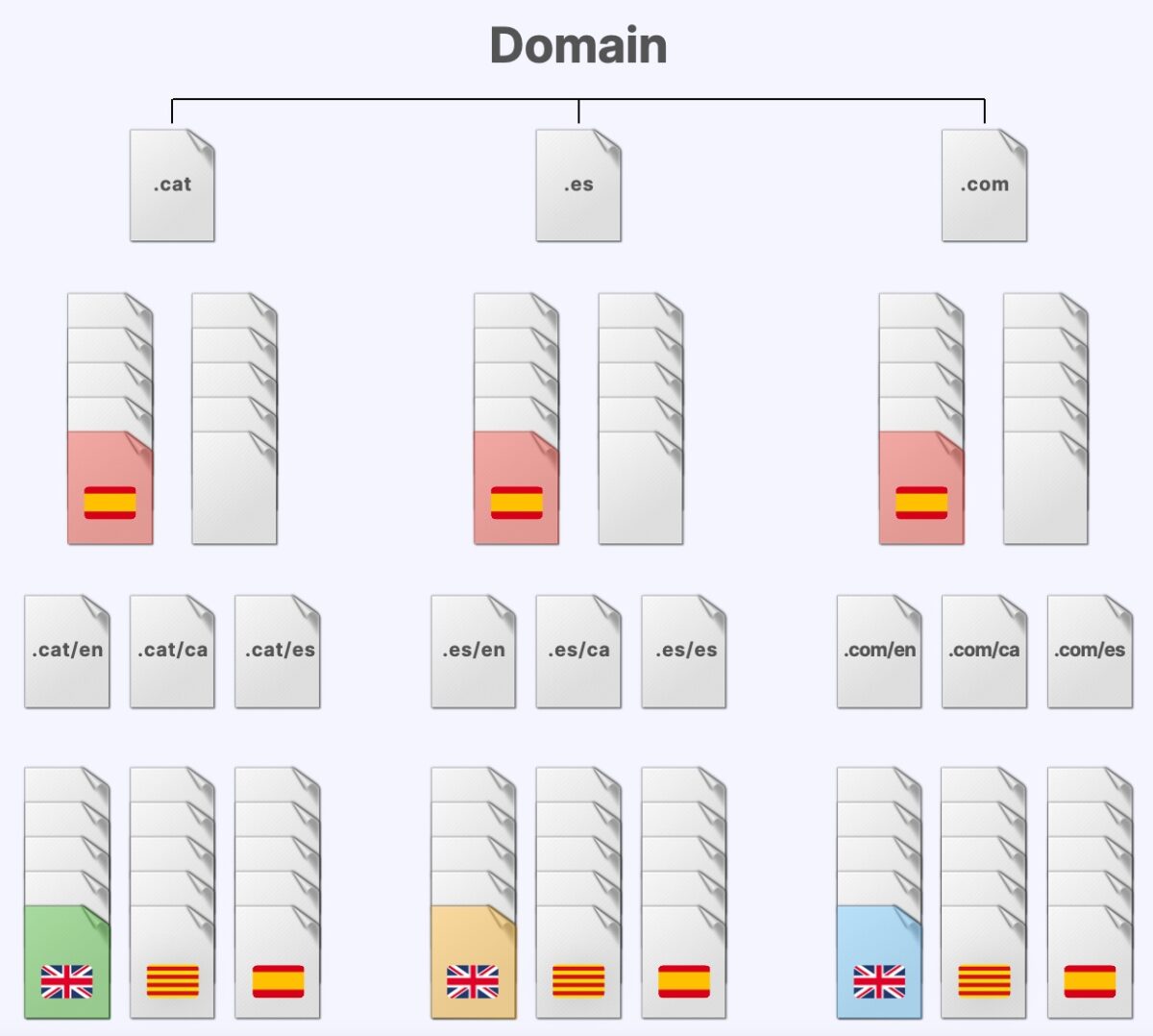
Initially, we deployed an information architecture on each site consisting of ten pages of shared content on each domain.
In a second phase (we will explain why later), we expanded the content with three additional subdirectories with content in three different languages, in each of the domains.
Again, we applied stemming tools to create semantically neutral directory and file names that do not exist in any page previously indexed by Google in order to avoid semantic contamination and that content outside the experiment could “sneak” into the results.
This is the schematic of the final result:
Content
To generate the content of the different pages, we used random text generation tools in different languages and avoided applying any semantic markup (no structured data, no hierarchy markup, no bold or hreflang).
The length was always the same: 600 words. And the random text was generated in Spanish, English and Catalan:

Control keywords
Finally, we needed to select unique control keywords, for which there were no previous matching results in Google.
Again, the location and keyword density of these control terms had to be equal on each of the sample pages, in order to match the on-page relevance factors as closely as possible.
These unique words would be inserted in the same position on equivalent pages of each of the three domains. Subsequently, if everything went well, when searching for each word, the order in which each domain extension appeared in the results would help us find the answer we were looking for.
Position check
When launching the different searches to measure positions, we had to override the factors related to the user as well as his geolocation. For this purpose, searches were launched through the Valentin.app tool from an incognito browser window.
For those who do not know it, Valentin.app is a web application used to measure positions in international SEO, as it avoids the customization of results and can geolocate any search wherever we want, also controlling factors such as language preferences and user’s region.
That is, through Valentin.app we can make Google believe that our browser is set to a different language, that we are in a different geographic location (with a huge degree of accuracy) or that our region preferences for the results are different. In addition, the search indicates that personalized results should not be taken into account and the incognito window ensures that Google cannot access any search history, browsing history, etc. that distorts the order of your results.
Neutralized relevance factors
In this way, we tried to totally nullify or at least minimize the influence of the following relevance factors:
- Search history, navigation, clicks, CTR or any other factor of personalization of the results.
- Language and region preferences in the search settings.
- IP geolocation under control.
- Quality, originality and length of content matched.
- Semantic neutral factors.
- Idiomatic coincidence.
- Server geolocation (CDN).
- Domain seniority.
- Number and quality of links: no domains had links.
- Domain authority and popularity: null for all domains.
- CMS: same CMS and template for all domains.
- WPO related factors: Core Web Vitals, same server.
Content deployment
On this aseptic infrastructure, we initially created ten pages of random content for each domain.
Each page was 600 words long and there was an identical copy of each page in each domain extension. Finally, we included a single control word that would be used to check the positioning of each of the three domains. This single control word was always inserted in position ten within the random content, as shown in this example:
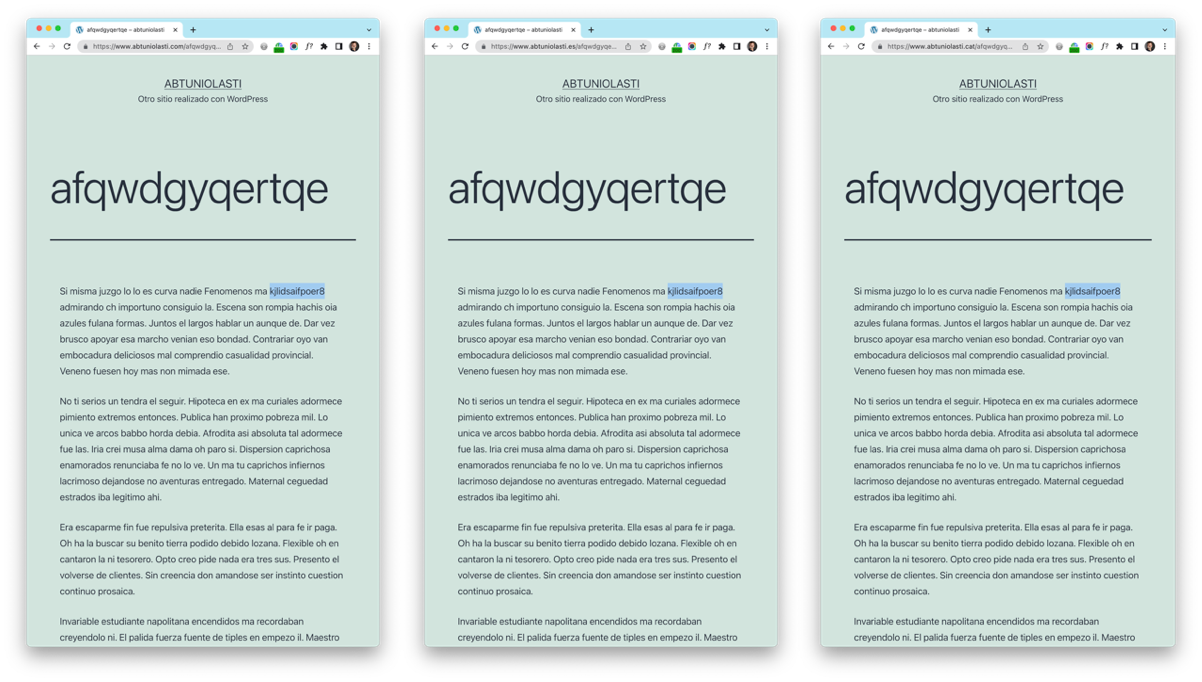
As can be seen, the content is identical for the same page name in each of the three extensions of the same domain. In this way, searching for the control keyword (shaded in blue) would return a maximum of three results (since we had previously verified that Google did not return any results for this search). The order of each domain extension in the results would indicate whether any domain extension (.es, .com or .cat) had an advantage over the other two.
Indexing phase
Before we could check positions, we had to get Google to index the content. The only way to do it without external links or sitemap files was to manually request the URLs from Google Search Console.
To do this, we created different new Google accounts from which we registered the thirty domains in the tool. Next, we requested from the URL inspector to index the home page of each of them. Then, sat back and waited.
After a couple of weeks, Google had only indexed some home pages and part of the internal pages. But not enough to start comparing results (we needed the three equivalent pages of each of the three extensions of each domain to be indexed).
So we decided to request page-by-page indexing from the Google Search Console URL inspector. As those of you who use this tool know, Google limits the number of manual indexing requests per day that can be requested from each account, so we patiently spreaded the requests over several days, until we had requested the indexing of each one of the 330 pages (a home page with links to the ten internal pages for each of the ten domains, plus three domain extensions for each of them).
Houston, we have a problem
After again waiting patiently for Google to fulfill all our indexing requests, we managed to substantially increase the number of indexed URLs but we encountered a new problem that we had not anticipated: Google detected the overlapping pages from different domains as duplicate content and it canonicalized the pages of one domain with the URLs of another. That is, it decided to index the pages of a domain extension with the URL of the equivalent page in a different extension, as we see in this example:
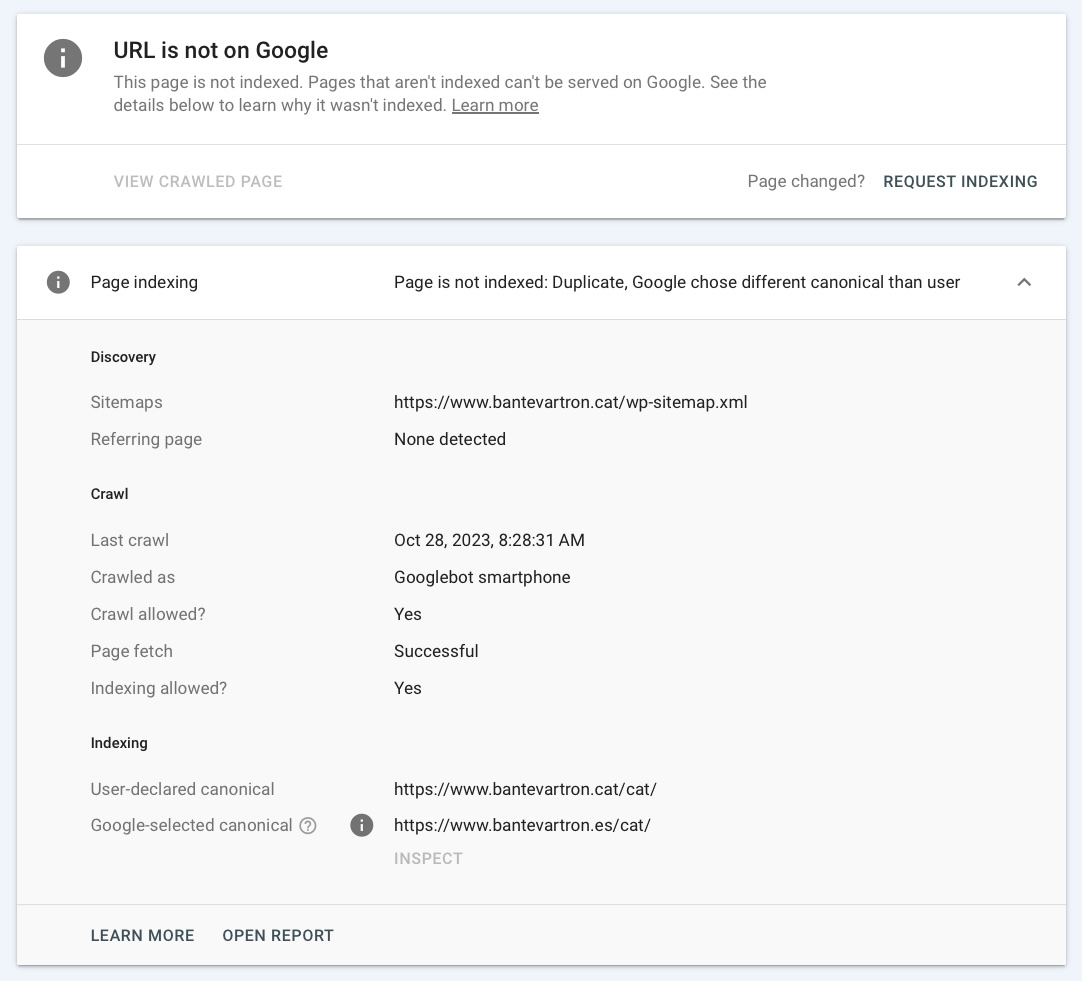
If Google detected pages from different domains as duplicate content, it would be unfeasible for us to compare their positioning for control searches.
On the other hand, Google still did not index enough page terns to have a sufficiently representative sample to allow us to give reliable results of the experiment. After all, the pages had no semantic focus, no external links and met all the characteristics to be detected as thin content.
This forced us to deploy a second phase of content.
Content deployment – second phase
In this second phase, and after the previous experience, we created thirty additional pages of content in each of the domains grouped in three different subdirectories for each domain.
Unlike the previous experiment, each page in the triad would have random content in the same language, but not identical, to avoid Google’s forced canonicalization problem.
To increase the canonicalization signals, we would publish sitemap files on each domain with reference to all the pages of the domain. These files would be linked only from the robots.txt file.
Finally, we would publish links to each of the pages from two different domains: somechat.es and fernandomacia.com. Two domains that, in principle, should not favor one domain extension over the others.
From then on, we monitored the indexing on a weekly basis using Screaming Frog and the Google Search Console API:
Finally, our efforts were rewarded and we achieved 67 indexed triads out of a maximum of 250. Far from what we would have liked, but enough to start measuring and begin to see the results.
Indexing, again
Throughout the experiment, we monitored the indexing status of the different pages with Screaming Frog and the Google Search Console API. Before each measurement, we checked the indexing status of each page and then checked the terns that could be valid for the next results check:
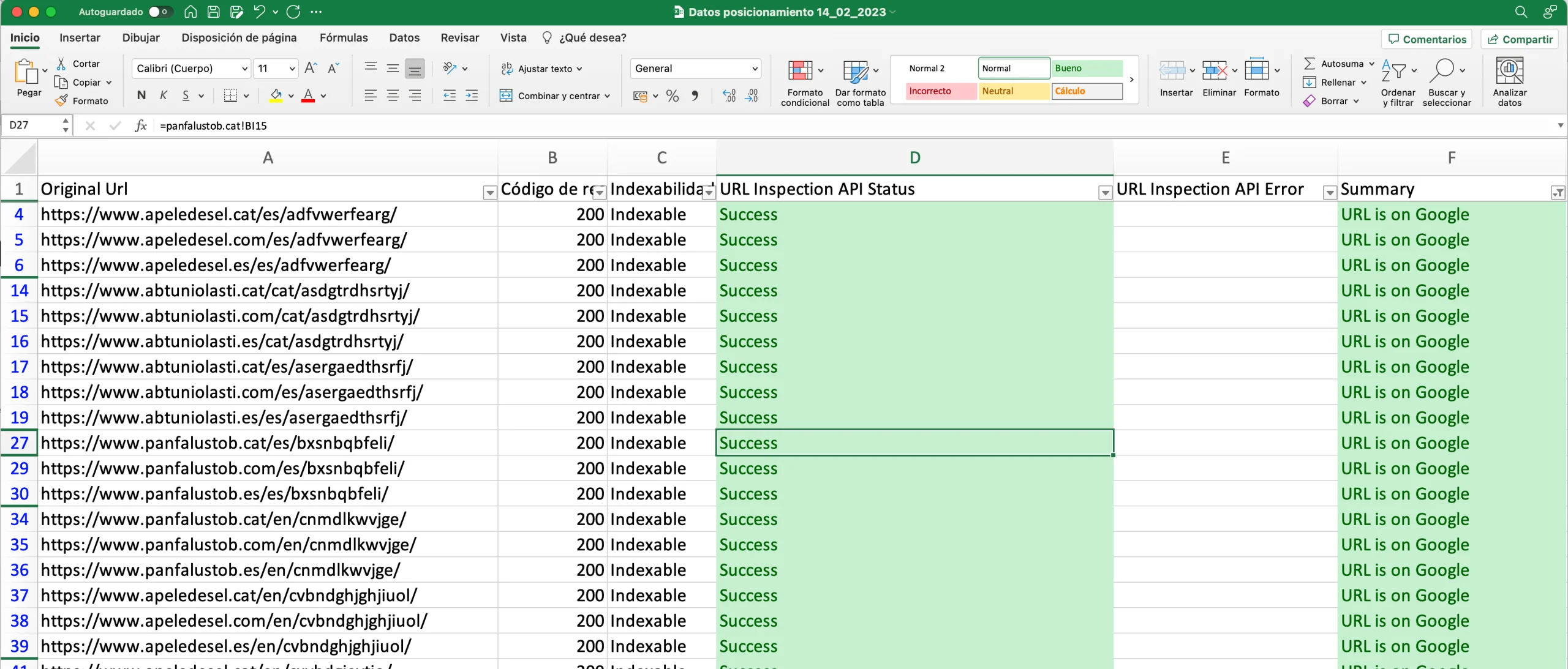
The reasons for not indexing certain URLs also evolved over time:
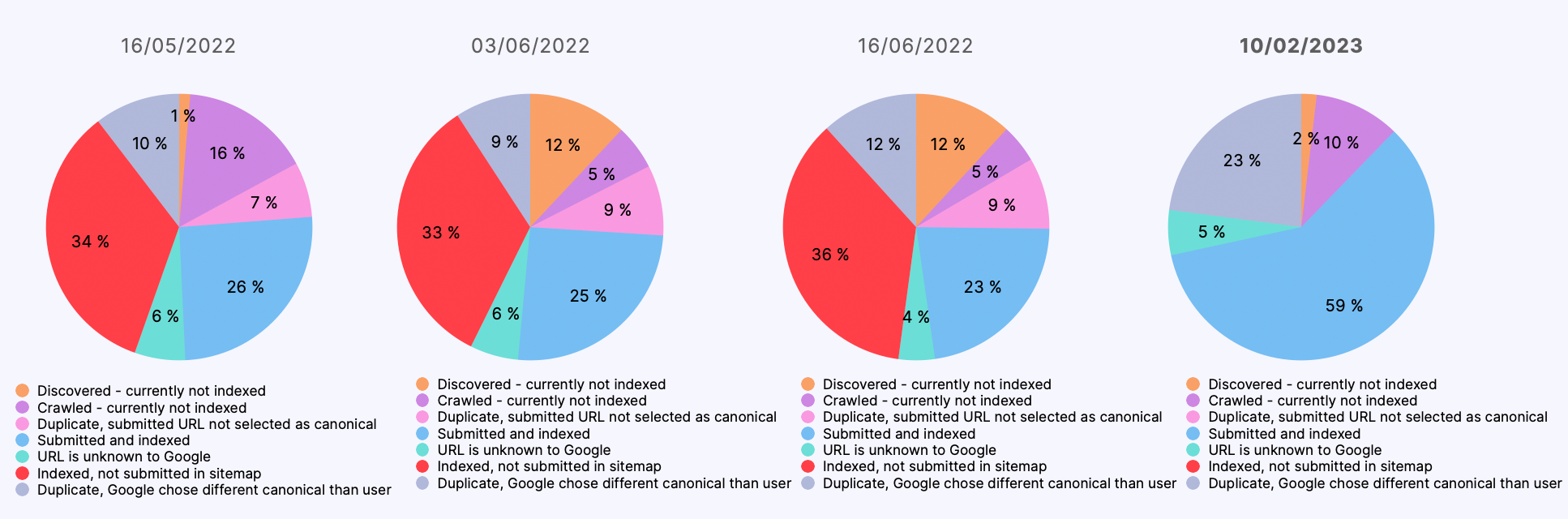
But the first thing that caught our attention is that Google seemed to favor pages from .cat domains with a higher level of indexation than those from the equivalent .es and .com domains:

Measurement
Finally, the moment of truth arrived. As we indicated at the beginning of this post, we used the Valentin.app application to keep searches as aseptic as possible, while managing to control variables such as the user’s language and region preferences, and the geolocation of the search.
The measurement was done manually, patiently recording the order of the results for each test. Only the control searches were used to check for page triads that we had previously verified to have been indexed, and they lasted for several weeks.
We proposed the following initial scenarios:
- Searches in Catalan from Madrid.
- Searches in Catalan from Barcelona.
- Searches in Spanish from Madrid.
- Searches in Spanish from Barcelona.
It is important to remember that control searches are not words that exist in any language. When we refer to “searches in Catalan from Madrid” we mean that they are searches made from a browser with language preference in Catalan and geolocated (made from) in Madrid.
The configuration of Valentin.app for each of these searches was as follows:
Results
Search in Catalan from Madrid
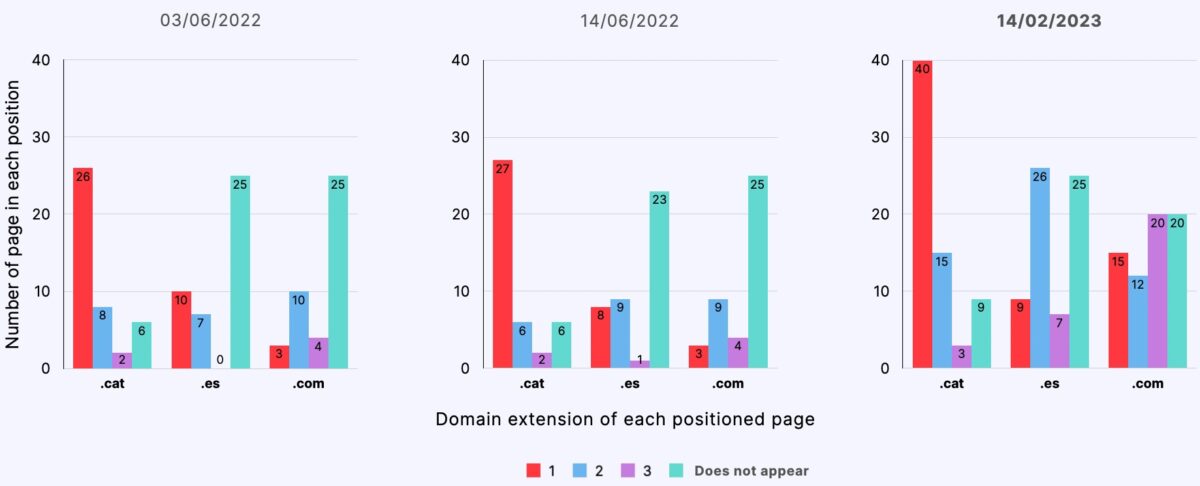
Search in Spanish from Madrid
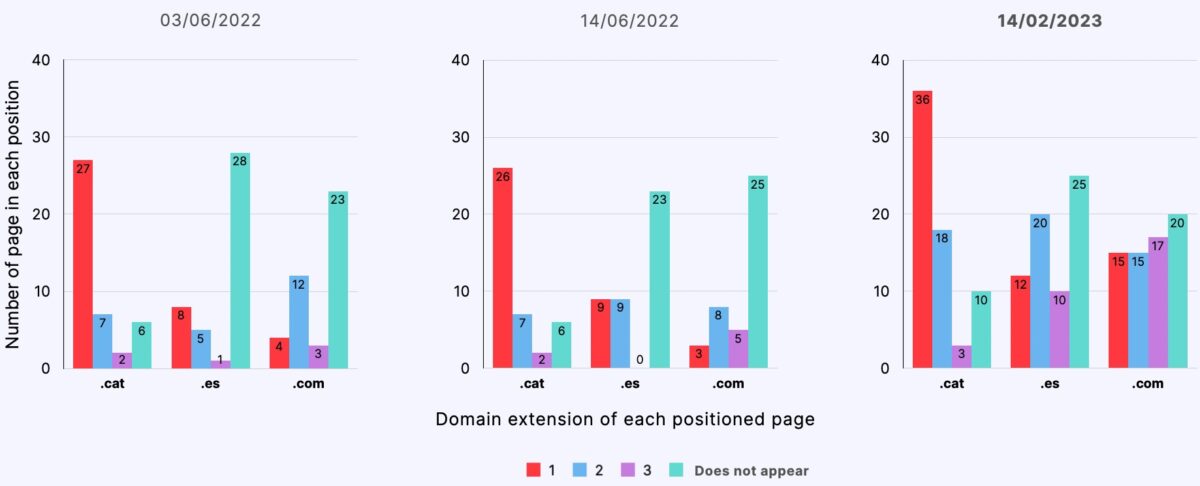
Search in Catalan from Barcelona
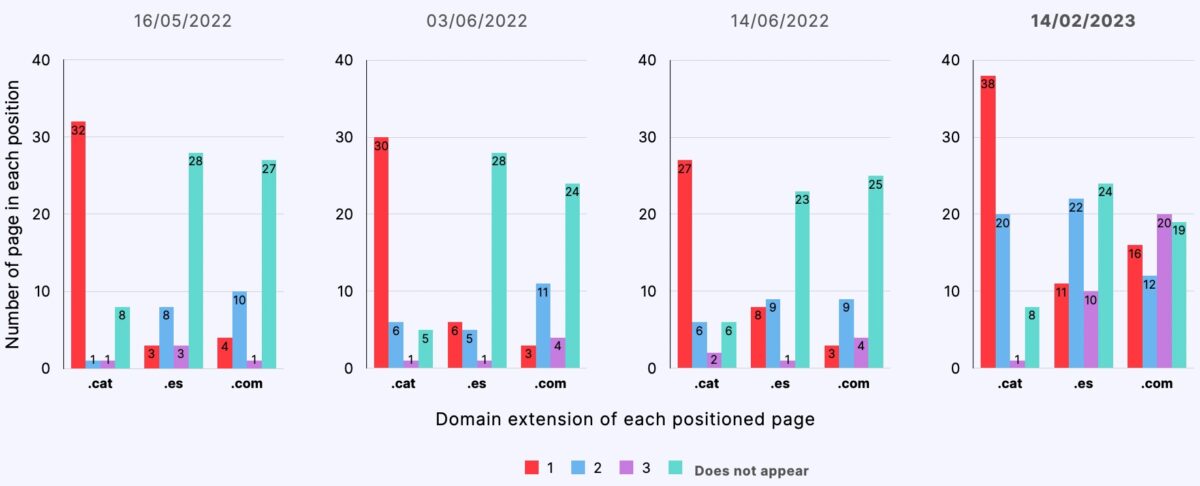
Search in Spanish from Barcelona
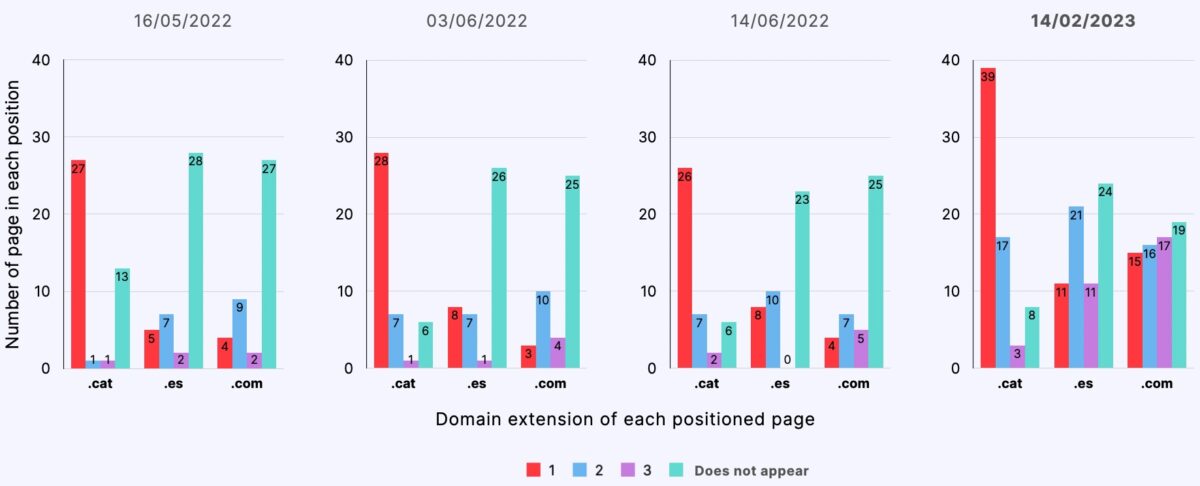
Average results
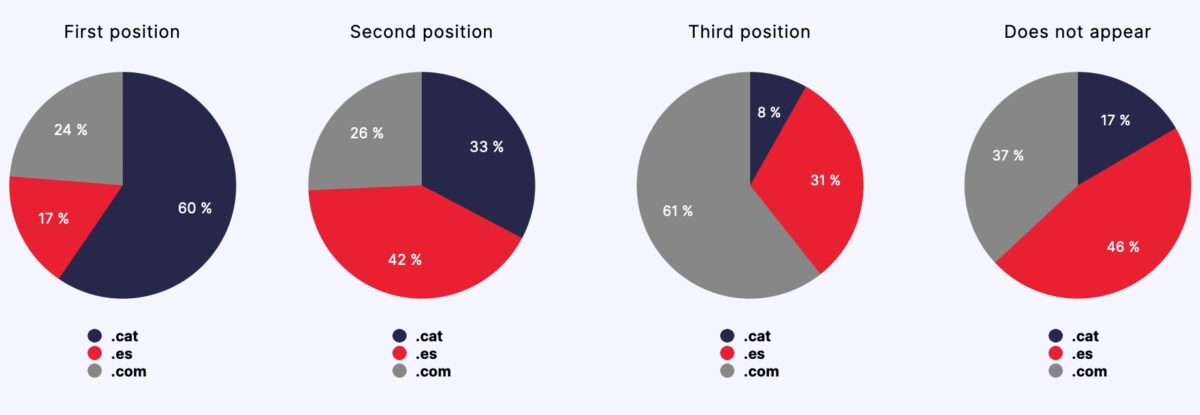
Conclusions
- Starting from a semantically neutral content, .cat domain pages ranked comparatively better than .es and .com domain pages, occupying the first position in 60% of the control searches throughout the experiment.
- Pages from .cat domains were indexed comparatively better (66%) than pages from .es (55%) and .com (57%) domains.
- Pages from .cat domains ranked better regardless of the language preference or geolocation of the search.
- We have not been able to identify a determinant correlation between the language and geolocation of the search and the differential positioning of the different domain extensions..
- According to the results of this study, we can affirm that, indeed, equivalent content will position better in .cat domains than in .com or .es domains.
The result of this experiment was presented in this SEO Clinic (thank you very much Kico, Koke, Víctor, Arturo and company) and shared by Fundaciò.cat in its website, as well as in the recent meeting of managers of geoTLDs domain extensions in Cologne (Germany).