Written by Fernando Maciá
Carlos Redondo (@carlosredondo), SEO Manager, online marketing director and founder of Safecont talks to us about how to detect patterns to improve the SEO of our website.
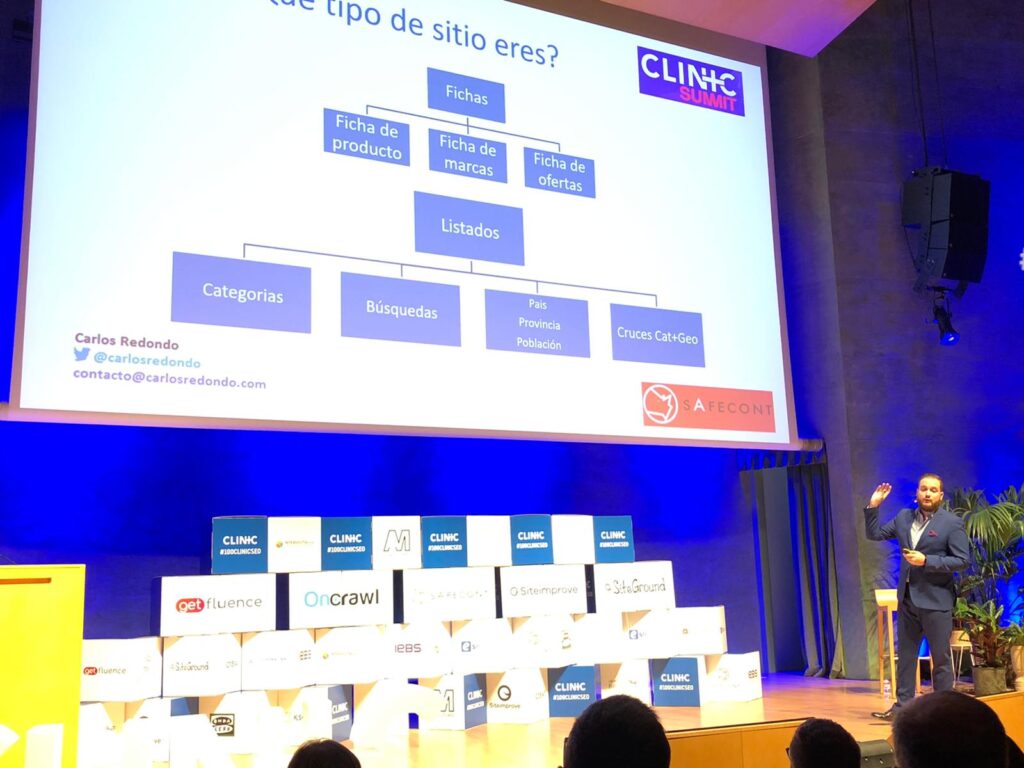
It is important to detect the patterns that occur in Web sites. What kind of Web site are you, an e-commerce, a corporate site? Depending on the structure, it can generate quite a few problems.
The eMagister case
At eMagister we have tested the types of problems that arise. It was penalized in 2011-12 and is in good health today.
Thousands of courses were indexed with aggressive categorization, extensive keyword research and all kinds of pages were deployed without any control over indexing. There was a large generation of different URLs per keyword.
It is important to monitor traffic quality indicators per page: bounce rate, traffic per page, etc. Updates can affect different areas of your Web site in different ways.
The easiest way is to use Analytics content grouping to see how traffic behaves for each content group: traffic, bounce, dwell time, etc. It is very simple to set up and does not affect historical data.
Content groupings
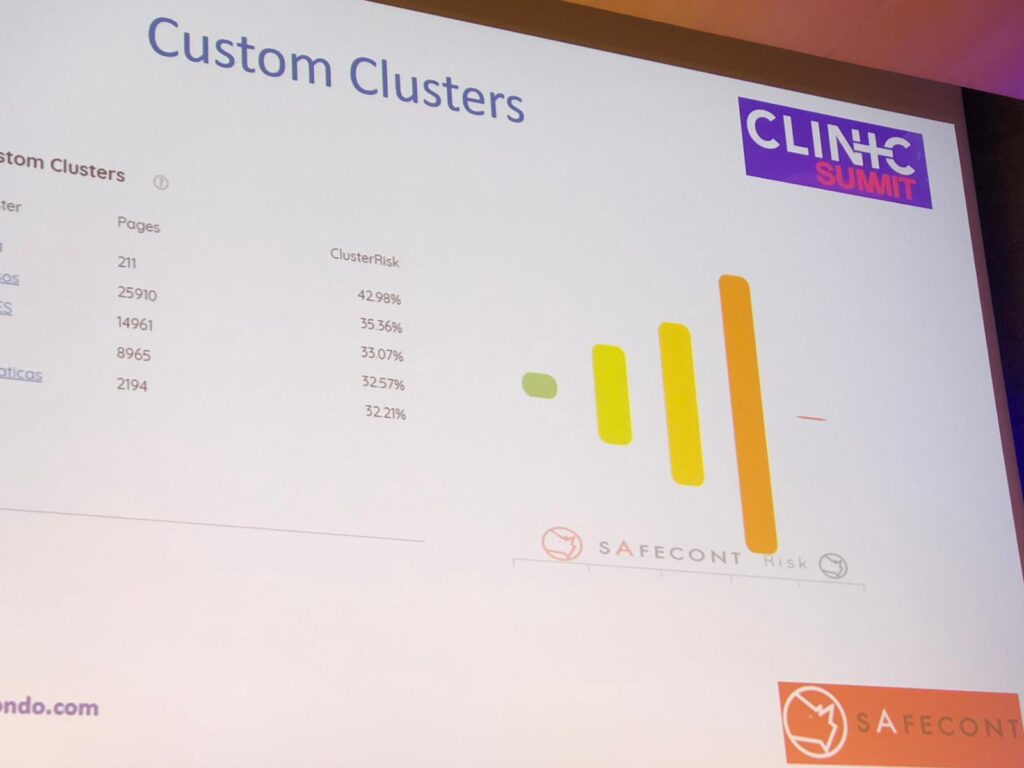
In Safecont we can configure custom clusters to generate groupings as we wish. Thus, we analyzed groupings of content to analyze separately.
There are also other groupings by semantic clusters: it groups URLs that match at the semantic level by topic. Clusters of different sizes are generated and we visually distinguish between safer and more problematic clusters.
When there are many URLs with a high degree of similarity, we are creating difficulty for Google to identify the page that should rank for a given keyword. In eMagister there were groups of pages with 100% similarity: these generated a big problem of cannibalization and duplicate content for Google.
The type of content shown by Carlos Redondo is used in many portals: for example, real estate, e-Commerce, marketplaces, etc. Therefore, a content analysis can be improved by minimizing the levels of internal and external duplication as well as the possibility of thin content.
Duplicate internal, external and thin content
In eMagister, courses were uploaded to many platforms. This generated a lot of external duplicate content. Different editions of the same course, if not well managed, also resulted in internal duplicate content. It is necessary to carry out hygiene work: de-index old content, rewrite or reformulate new content and reorder current content with better quality.
How to improve internal duplication? Unify the content. One concept = one URL. Enrich content and merge scattered content that can work well together. In this case, the community and the directory.
Tools
ScreamingFrog, Wordstat, Safecont, etc. were used. A crawl was made and we extracted the minimum units of signification to identify what each page was about. Then, we would check how many pages shared the same semantic and we would group the contents to redirect or canonicalize URLs. This reduced the number of URLs.
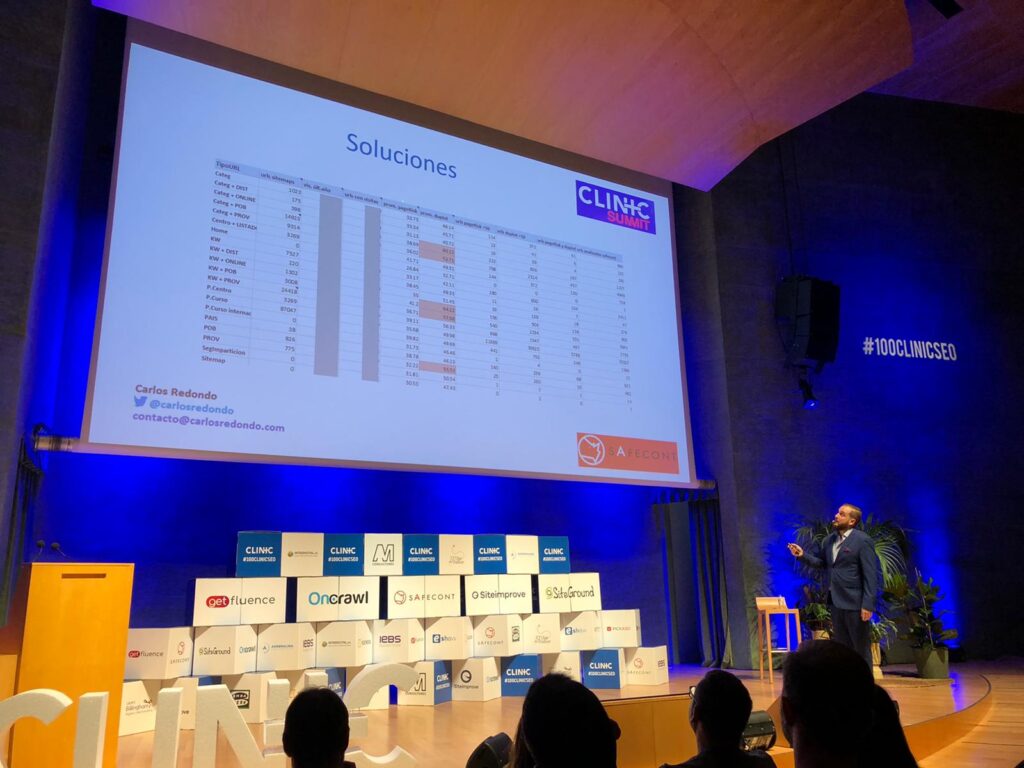
Solutions
On the community and directory side, content merging also managed to reduce the number of URLs and, by combining the content of URLs, disperse, reduce thin content and improve the relevance of the content we were indexing.
Carlos recommends working with data, combining all possible indicators to focus the work of merging, combining content, internal interlinking and link juice recovery upwards (we forget to throw links upwards).
If the problem comes from the link profile, it is advisable to do a disavow. Better to do traditional linking actions: industry, traditional media, universities, etc.
There are technical problems that go unnoticed and can affect positioning: page listings, AMP versions, URL parameters, application of multiple indexed filters, contenttags, URLs with uppercase, lowercase, etc. Carlos shows multiple problems in well-known portals such as Amazon, SEOroundtable, Zalando, Indesit…