

Escrito por Ramón Saquete
Índice

El hecho de que existan datos estructurados en schema.org que son equivalentes o prácticamente equivalentes a etiquetas semánticas de HTML5, hace sospechar que esta información puede ser importante para la araña de Google (recordad que schema.org está creado en parte por ellos).
Se desconoce a ciencia cierta si Google tiene en cuenta este tipo de datos estructurados y las etiquetas semánticas de5, en cuyo caso su efecto sólo puede ser positivo, ya que permitirían a la araña saber cómo están organizadas las páginas y responder a varias preguntas que necesita resolver para indexar correctamente los contenidos.
Preguntas como: «¿cómo separo la cabecera y el pie del contenido principal?», «¿existe contenido que no es parte del contenido principal sino solo transversal a éste?» o «¿qué grupos de enlaces sirven para navegar entre varias páginas y no son simplemente un listado de enlaces en una página concreta?».
En definitiva, nos permite identificar mejor el contenido principal de las páginas, que es el que debe posicionarse y destacar por encima del resto de contenidos de cada una de nuestras páginas.
Marcar esta información con etiquetas semánticas de HTML5 y al mismo tiempo con sus datos estructurados equivalentes puede parecer redundante, pero como no sabemos en qué medida Google tiene en cuenta unos y otros, recomendamos implementar ambos.
¿Cuáles son los tipos de datos estructurados equivalentes a etiquetas semánticas de HTML5?
Las etiquetas <header> y <footer>, se utilizan para marcar la cabecera y el pie de cualquier elemento de sección raíz o de sección de contenido en HTML5. Cuando se usan, las más importantes son las que se colocan como hijas directas del elemento de sección raíz <body>, sin elementos de sección de contenido intermedios (<nav>, <article>, <section> y <aside>), ya que así indican que se trata de la cabecera y pie principal que se repite a lo largo de todas las páginas de nuestro sitio.
Curiosamente, existen los tipos de datos estructurados https://schema.org/WPHeader y http://schema.org/WPFooter que representan de forma equivalente la cabecera y el pie del sitio web. No sería correcto utilizar este tipo de datos estructurados dentro de etiquetas <header> y <footer> que estuviesen, a su vez, dentro de un elemento de sección de contenido ya que este tipo de dato estructurado es equivalente sólo para el <header> y <footer> principales de la página.
De modo similar, podemos usar el dato estructurado https://schema.org/SiteNavigationElement para todos los elementos <nav>, pero el único realmente importante es el que contiene el menú principal de la página, aunque también podríamos marcar los enlaces del pie de página. Para las migas de pan es mejor utilizar el tipo https://schema.org/BreadcrumbList mientras que los paginadores Google actualmente los detecta sin siquiera especificar cuál es la página siguiente y anterior, por lo que tampoco es necesario aplicarlo a este caso.
Para la etiqueta<aside>, utilizada para cualquier tipo de contenido transversal al contenido principal (se encuentre en un sidebar o no), tenemos el tipo https://schema.org/WPSideBar. En cambio, si el elemento aside sólo contiene anuncios, lo correcto sería utilizar el tipo https://schema.org/WPAdBlock en su lugar.
Para <body> tenemos el tipo de dato http://schema.org/WebPage. Marcar el cuerpo del documento parece poco útil, pero hay tipos estructurados derivados de este con el que podemos concretar qué tipo de página es. Por ejemplo un FAQ (https://schema.org/FAQPage), una página de contacto (https://schema.org/ContactPage) o un «Acerca de» (https://schema.org/AboutPage), etc.
Pero lo más importante es que el tipo https://schema.org/WebPage tiene varias propiedades que imitan el significado de la etiqueta <main>, útiles para marcar el contenido principal de la página.
Las propiedades de datos estructurados equivalentes a la etiqueta <main>, son:
- La propiedad mainContentOfPage de https://schema.org/WebPage, que debe ser del tipo https://schema.org/WebPageElement, es decir, un tipo de datos estructurado comodín aplicable a cualquier tipo de etiqueta.
- El tipo https://schema.org/WebPage también cuenta con la propiedad mainEntity para marcar el tipo de dato estructurado que representa el contenido principal de la página (para los casos en los que dicho contenido use algún tipo de dato estructurado concreto).
- Alternativamente y de forma equivalente a mainEntity y https://schema.org/WebPage, dentro del tipo de dato estructurado principal de la página podemos usar la propiedad mainEntityOfPage, que tomará como valor la URL actual. Google recomienda usar esta propiedad con el tipo https://schema.org/Article cuando sea el contenido principal de la página.
Más adelante vemos cada uno de estos puntos con un ejemplo.
Por último, para el viejo elemento <table> , también tenemos su equivalente en el tipo de datos estructurado https://schema.org/Table.
Recomendaciones generales para implementar estos tipos de datos estructurados
JSON-LD
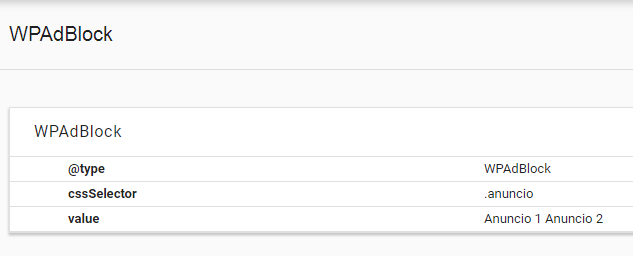
Veamos un ejemplo de uso de este tipo de datos estructurados con JSON Linked Data, que es el formato recomendado por Google. Para ello supongamos que tenemos varios bloques de anuncios sobre el mismo tema diseminados por la página. En este caso podemos ponerles a todos la misma clase y asociarla al tipo WPAdBlock mediante el siguiente código en JSON+LD:
…
Contenido de la página …
<aside class="anuncio">Anuncio 1</aside>
Contenido de la página …
<aside class="anuncio">Anuncio 2</aside>
…
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WPAdBlock",
"cssSelector": ".anuncio"
}
</script>
Con la propiedad cssSelector especificamos el selector de CSS que asigna el tipo de dato actual al elemento seleccionado (también es posible especificar una expresión XPath con la propiedad xpath).
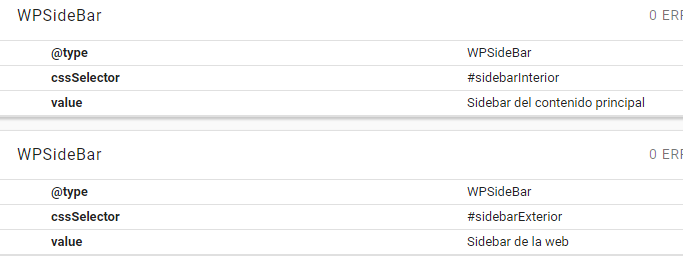
Si quisiéramos establecer bloques semánticamente independientes, por ejemplo, sidebars con distintas intenciones, los etiquetaríamos de forma separada:
<body>
<main>
<aside id="sidebarInterior">Sidebar del contenido principal</aside>
</main>
<aside id="sidebarExterior">Sidebar de la web</aside>
….
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WPSidebar",
"cssSelector": "#sidebarInterior"
}
</script>
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WPSidebar",
"cssSelector": "#sidebarExterior"
}
</script>
Podemos aplicar esta forma de implementación a todos los tipos derivados de WebPageElement (todos heredan las propiedades cssSelector y xpath), esto es: SiteNavigationElement, Table, WPAdBlock, WPFooter, WPHeader y WPSideBar. Llevando cuidado de crear un único elemento asociado para WPHeader y WPFooter.
Microdatos
También es válido implementar estos tipos de datos con microdatos de la siguiente forma:
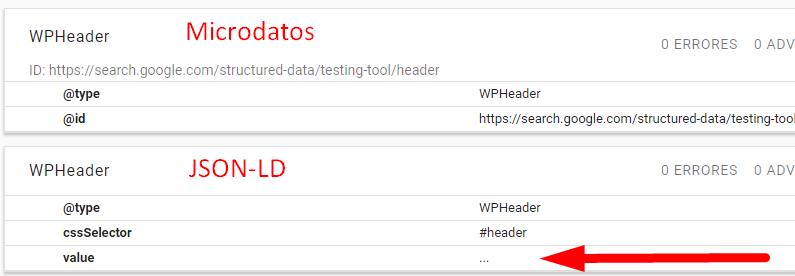
<header itemscope itemtype="https://schema.org/WPHeader" id="header"> ... </header>
Esta implementación es más corta para los casos en los que el tipo de dato aparece sólo una vez, como ocurre siempre con la cabecera y el pie. También es la forma en la que WordPress implementa estos datos estructurados. Sin embargo, la herramienta de datos estructurados de Google no detecta este tipo de implementación si el elemento marcado no lleva un identificador como en el ejemplo (id=»header»). Y, además, con esta implementación la herramienta no le asigna ningún valor al tipo de dato, mientras que con JSON-LD coge como valor el propio contenido, por lo que parece más fiable la implementación con JSON-LD.
Implementación del contenido principal (etiqueta <main>) con datos estructurados
JSON-LD
Veamos un ejemplo de cómo usar la propiedad mainEntityOfPage:
<script type="application/ld+json"> "@context": "https://schema.org", "@type": "Article", "mainEntityOfPage": "https://www.humanlevel.com/articulos/indexabilidad/datos-estructurados-equivalentes-a-etiquetas-semanticas-de-html5", "author": "...", ... </script>
Si englobamos este tipo de dato estructurado dentro del tipo WebPage podríamos expresar exactamente lo mismo de la siguiente manera con la propiedad mainEntity:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "WebPage",
"mainEntity": {
"@type": "Article",
"author": "...",
...
}
}
</script>
Si no tenemos ningún tipo de datos estructurado que podamos asociar al contenido principal de la página, lo podemos implementar con WebPage y mainContentOfPage de esta forma:
<main id="principal">
Lorem ipsum
</main>
<script type='application/ld+json'>
{
"@context": "https://schema.org",
"@type": "WebPage",
"mainContentOfPage":{
"@type": "WebPageElement",
"cssSelector": "#principal"
}
}
</script>
Microdatos
Ahora vamos a ver las anteriores implementaciones con microdatos:
Propiedad mainEntityOfPage:
<main itemscope itemtype="http://schema.org/Article">
<meta itemprop="mainEntityOfPage" content="https://www.humanlevel.com/articulos/desarrollo-web/como-interpretar-schema-org-para-crear-datos-estructurados"/>
<p itemprop="author">…</p>
…
</main>
Propiedad mainEntity:
<body itemscope itemtype="http://schema.org/WebPage">
<main itemprop="mainEntity" itemscope itemtype="http://schema.org/Article">
<p itemprop="author">…</p>
…
</main>
</body>
Propiedad mainContentOfPage:
<body itemscope itemtype="http://schema.org/WebPage">
<main itemprop="mainContentOfPage" itemscope itemtype="http://schema.org/WebPageElement">
…
</main>
</body>
Conclusión
Los datos estructurados, en algunos casos, aportan más información que las etiquetas de HTML5 y es más probable que el robot de Google los tenga en cuenta, a la hora de decidir cómo está organizada cada página y, sobre todo, para saber cuál es el contenido principal de la misma, que es la parte que se debe posicionar por encima del resto de elementos, por lo que siempre será mejor tenerlos implementados y preferiblemente con JSON-LD.
Referencias adicionales
- HTML5
- JSON
- Herramienta de validación de datos estructurados de Google
- Validador de implementación de Schema con marcado JSON
- Introducción a los datos estructurados – Google.
- Qué son los datos estructurados y schema.org – María Navarro.
- Datos estructurados – preguntas y respuestas con Google.
- Qué son los Featured Snippets – Rocío Rodríguez.
- Fragmentos enriquecidos para conseguir más tráfico – Jose E. Vicente.



