Escrito por Fernando Maciá
Índice
Esta fue la cuestión que la Fundació .cat planteó a Human Level a finales de 2021. Aunque en su sitio Web promocionaban la adopción de esta extensión de dominios por parte de las empresas catalanas argumentando que podía suponer una ventaja en el posicionamiento de sus sitios Web para búsquedas en catalán, esta afirmación carecía de base científica y no se disponía de ningún estudio o análisis que la confirmara o refutara. Y esto era exactamente lo que solicitaban a Human Level: diseñar y ejecutar un experimento que aportara pruebas empíricas a favor o en contra.
Como SEO, me sentí igual que cuando mis padres me regalaron por Navidad un laboratorio Quimicefa. Contaríamos con un presupuesto para poder crear un entorno aséptico donde diseñar y desarrollar un experimento SEO para tratar de demostrar una relación causa-efecto, no una mera correlación, entre el uso de un dominio .cat y un mejor posicionamiento en los buscadores. ¡Iba a ser complicado, pero nos lo íbamos a pasar pipa!
Pero empecemos por el principio.
Dominios .cat: ¿qué son?
Los dominios .cat pertenecen a una categoría de dominios de primer nivel (TLD – Top Level Domain) denominados patrocinados (sTLD – sponsored Top Level Domain) y, dentro de estos, dominios orientados a un área geográfica determinada: geoTLD. Este tipo de dominios son impulsados y gestionados por una entidad patrocinadora en representación de una comunidad específica que comparte determinados intereses étnicos, geográficos, profesionales, técnicos u otros cualquiera propuestos por agencias u organizaciones privadas que establecen y aplican normas que restringen la elegibilidad de los solicitantes de registro para usar este dominio de primer nivel.
La Internet Assigned Numbers Authority (IANA) es la autoridad encargada de mantener el Sistema de Nombres de Dominio de Internet, gestionando tanto los dominios patrocinados (sTLD) como los dominios de primer nivel genéricos (gTLD – generic Top Level Domain) o de código de país (ccTLD – Country Code Top Level Domain).
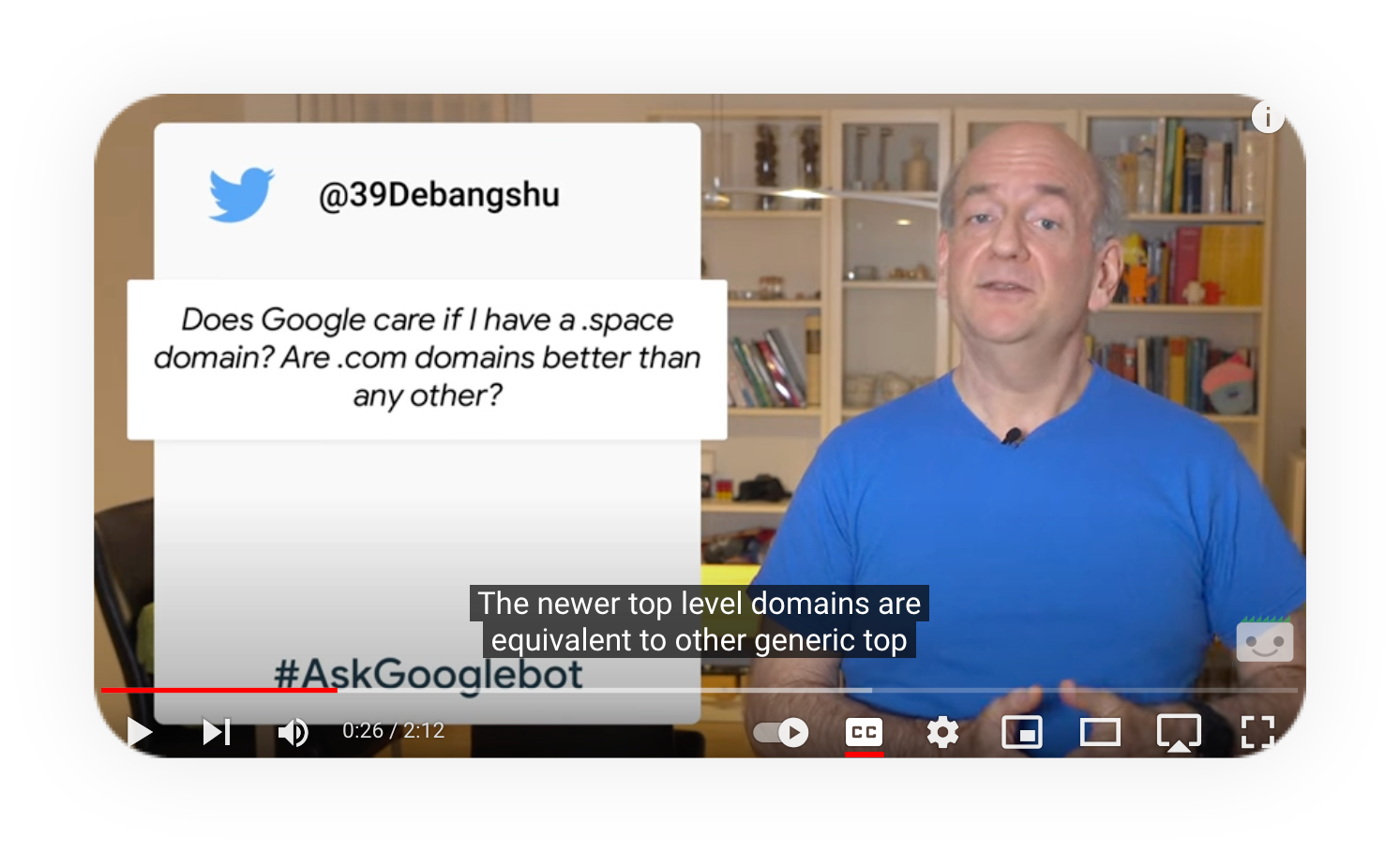
¿Cómo trata Google los dominios patrocinados (sTLD)?
Esta es una pregunta que han respondido en numerosas ocasiones portavoces oficiales de Google. En este vídeo, John Mueller afirma que “tratamos todos los nuevos dominios de primer nivel como cualquier otro dominio genérico de primer nivel. No supone ningún valor adicional tener palabras clave como extensión de dominio. No hay ningún valor adicional en tener nombres de ciudades o de países como extensión de dominio. Los tratamos como cualquier otro dominio genérico, esencialmente como leica.com. De modo que si encuentras un nombre de dominio que funciona bien para tu sitio web, que quieres mantener a largo plazo y corresponde a una de estas nuevas extensiones, definitivamente ve a por él. Creo que es perfectamente correcto”.
De modo que, al menos desde un punto de vista de la documentación oficial por parte de Google, el experimento no debería ser capaz de mostrar ningún impacto, positivo o negativo, sobre el posicionamiento en Google de un contenido en un dominio .cat respecto a ese mismo contenido en un dominio .com o .es, por ejemplo.
La realidad, sin embargo, terminaría demostrando lo contrario, como enseguida veremos.
Objetivos del experimento SEO: ¿Qué queríamos demostrar en realidad?
En principio, la cuestión planteada por la Fundació .cat parecía suficientemente clara. Sin embargo, se abría a múltiples interpretaciones. ¿Influyen los dominios .cat sobre el posicionamiento? Y ¿en qué escenarios de búsqueda?
Por ejemplo:
- ¿Posicionarían mejor cuando la búsqueda se planteara en catalán?
- ¿Posicionarían mejor cuando la búsqueda se planteara en Google.cat?
- ¿Posicionarían mejor cuando el contenido rastreado estuviera escrito en catalán?
- ¿Posicionarían mejor para búsquedas hechas desde Cataluña?
Así como, evidentemente, muchos otros y las distintas combinaciones de todos ellos.
De modo que uno de los primeros puntos a establecer en el estudio consistiría en plantear las pruebas desde unos determinados escenarios de búsqueda que fijaran estas condiciones iniciales y analizaran el impacto de cada uno de ellos sobre el resultado.
Condicionantes: cómo mantener la asepsia de la prueba
El reto más complicado a la hora de plantear un experimento SEO que pretenda demostrar una relación entre un determinado factor de relevancia y su influencia sobre la posición alcanzada estriba en la dificultad de establecer y mantener unas condiciones de laboratorio que garanticen la asepsia de las pruebas, evitando la influencia de otros factores que contaminarían los resultados e impedirían demostrar la existencia concluyente de una relación causa-efecto.
Debido precisamente a esta dificultad, la mayoría de experimentos SEO tratan de identificar no una relación causa-efecto, sino una correlación. Y esta diferencia es fundamental:
- En una relación causa-efecto, tratamos de concluir que cuando realizamos una determinada acción, ocurre siempre un determinado efecto directamente relacionable con la acción ejecutada. Por ejemplo, siempre que llueve, se moja la calle. La calle está seca antes de empezar a llover y se moja debido al agua que cae en forma de lluvia, y no a la inversa.
- En una correlación, nos limitamos a observar que cuando ocurre un determinado acontecimiento, siempre se da en compañía de otro. Pero no siempre podemos determinar con certeza que uno sea la causa directa del otro. Por ejemplo, cada vez que llueve, la mayoría de los transeúntes abren sus paraguas. Un extraterrestre podría concluir que cada vez que los transeúntes abren sus paraguas, llueve, estableciendo erróneamente una relación causa-efecto entre la apertura de los paraguas y la caída de la lluvia.
Así que en segundo lugar debíamos diseñar un entorno de laboratorio SEO aséptico donde pudiéramos aislar y/o neutralizar al máximo el impacto sobre los resultados de otros factores de relevancia que pudieran afectar a la medición de las posiciones. Como, por ejemplo…
Factores de relevancia relacionados con el usuario
Determinados aspectos relacionados con el usuario afectan a los resultados que cada uno obtiene al hacer una búsqueda en Google. Entre otros, son importantes:
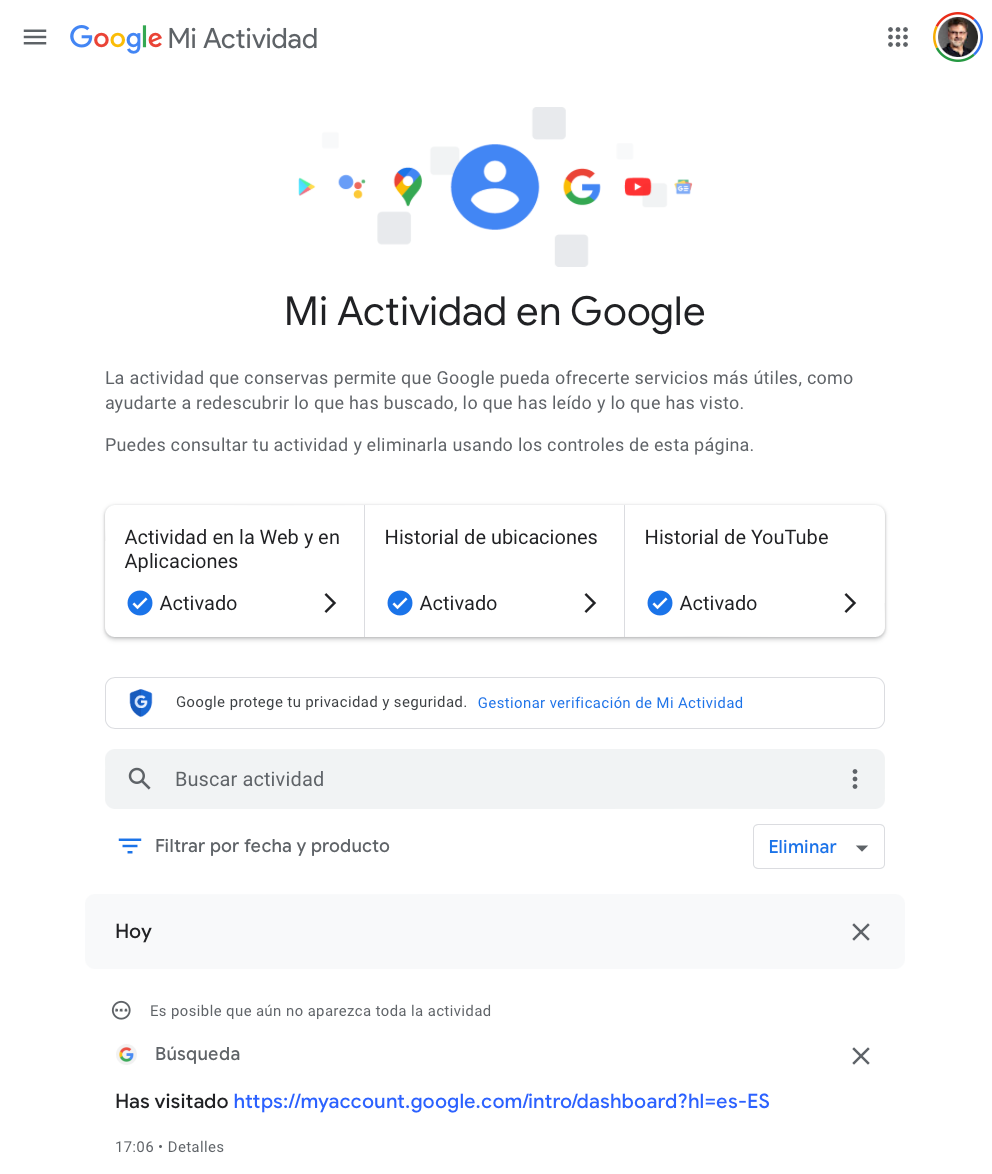
- Historial de búsquedas, navegación, clicks, etc. registrados por el navegador desde el que se hace la búsqueda o en nuestro propio perfil de usuario de Google. Toda esta actividad queda registrada en el apartado Mi Actividad en Google, así como en forma de cookies en nuestro navegador:
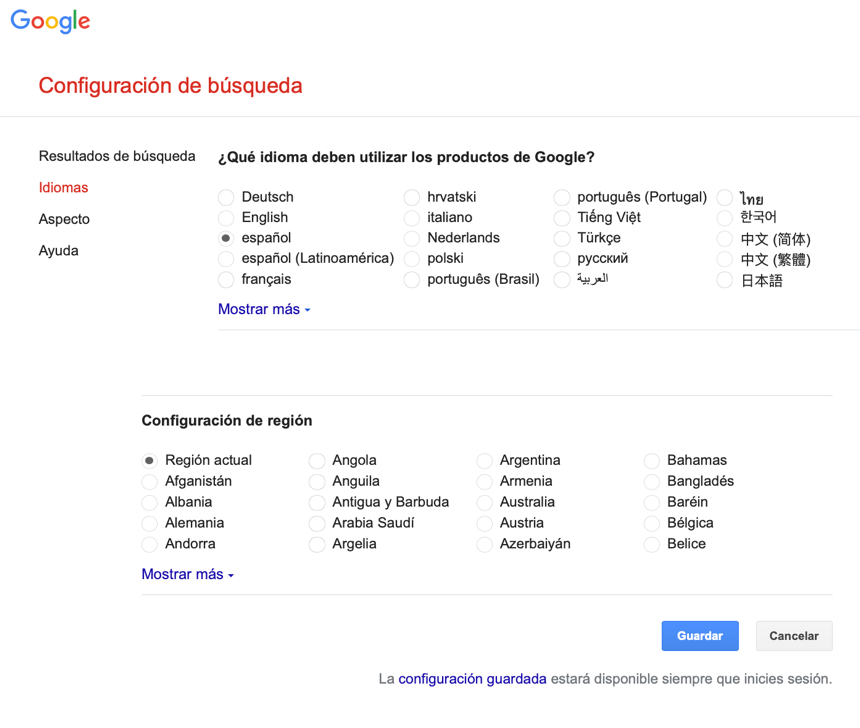
- Ajustes de idioma y región: configurados en nuestras preferencias de Google:
- Geolocalización por IP: cuando lanzamos una búsqueda a Google, el buscador realiza una geolocalización que utiliza para devolver resultados locales, por ejemplo. Podemos comprobar dónde nos geolocaliza en el pie de página:
Todos estos factores afectan también a los resultados que presenta Google. Si queríamos un entorno aséptico, debíamos ser capaces de neutralizarlos para que no afectaran a las posiciones obtenidas en las mediciones.
Factores de relevancia on-page
Comparar en las mismas condiciones cómo se posiciona un dominio .com, por ejemplo, respecto a un dominio .cat exigía también neutralizar todos los factores de relevancia on-page que pudieran afectar a los resultados.
Factores como:
- Calidad, originalidad, autoridad y extensión del contenido.
- Factores semánticos.
- Concidencia idiomática: un sitio web en el mismo idioma que el seleccionado como preferido por el usuario en su navegador favorecería un mejor posicionamiento.
- Geolocalización del servidor: ya que la cercanía del mismo al origen de la búsqueda podía influir en el resultado.
- CMS empleado: un gestor de contenido distinto puede favorecer ratios contenido/código distintos, marcado semántico distinto…
- Factores relacionados con la experiencia de usuario (UX) y la velocidad de descarga (WPO): en función del diseño, optimización de las imágenes, priorización en la descarga de recursos, etc.
Factores de relevancia off-page
Por último, debíamos también equiparar los factores de relevancia off-page de los dominios objeto de comparación.
Factores como:
- Antigüedad del dominio.
- Número y calidad de los enlaces.
- Autoridad temática del dominio.
- Popularidad y menciones sociales.
- Etc.
Metodología propuesta
Dominios
Dados los condicionantes anteriores, decidimos que la prueba debía hacerse sobre:
- Dominios nuevos, registrados simultáneamente, para equiparar su antigüedad.
- Dominios sin enlaces externos, para equiparar su autoridad y popularidad.
- Dominios sin ninguna relevancia semántica inicial por su propio nombre de dominio.
- Dominios cuyo contenido empleara exactamente la misma infraestructura de servidor, CMS y tema o plantilla para igualar cualquier aspecto relacionado con la geolocalización o prestaciones del servidor, velocidad de descarga, etc.
- Un número de dominios que nos diera la posibilidad de contar con una muestra suficientemente representativa que avalara la validez de los resultados obtenidos.
Con esto en mente, utilizamos herramientas de stemming como Snowball para comprobar la neutralidad semántica de los nombres de dominio seleccionados. Básicamente se trataba de encontrar palabras que no significaran nada en ningún idioma de la prueba (español, inglés o catalán).
Tras distintas pruebas, estos fueron los diez dominios seleccionados:
- Abtuniolasti.
- Zirgomaselon.
- Sendueplontu.
- Jolbiatrac.
- Trunipazel.
- Apeledesel.
- Tiriunbeladu.
- Capmanisol.
- Panfalustob.
- Bantevartron.
A continuación, registramos las extensiones .es, .com y .cat de cada uno de estos diez dominios, resultando en un total de treinta nuevos dominios registrados simultáneamente y semánticamente neutros. Obviamente, ninguno de ellos tenía ningún histórico ni enlace externo, por lo que todos compartían exactamente la misma (nula) popularidad/autoridad.
Servidor
Cada dominio fue a su vez alojado en un servidor del CDN Cloudflare. Un CDN o Content Delivery Network consiste básicamente de un servidor replicado geográficamente en distintos datacenters alrededor del mundo. Así, las peticiones que recibe un dominio alojado en un CDN son atendidas por el servidor más cercano al origen de la petición. Esto favorece una menor latencia en la respuesta y, lo que es más importante para el experimento, neutraliza la geolocalización del servidor como un factor relevante para el posicionamiento.
Gestor de contenidos
Por último, hicimos una instalación del CMS WordPress idéntica en cada uno de los dominios y utilizando su plantilla más básica.
Con ello, neutralizábamos también cualquier influencia derivada del gestor de contenidos, plantilla o plug-in empleados, prestaciones y geolocalización del servidor. Todos los dominios emplearían exactamente la misma infraestructura técnica.
Arquitectura de la información
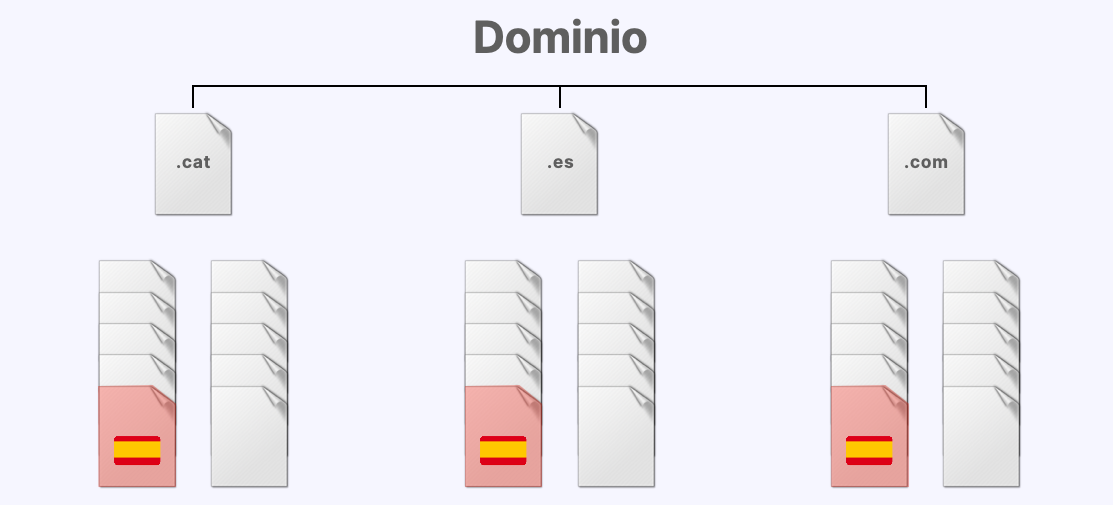
Inicialmente, desplegamos una arquitectura de la información en cada sitio compuesta por diez páginas de contenido compartido en cada dominio.
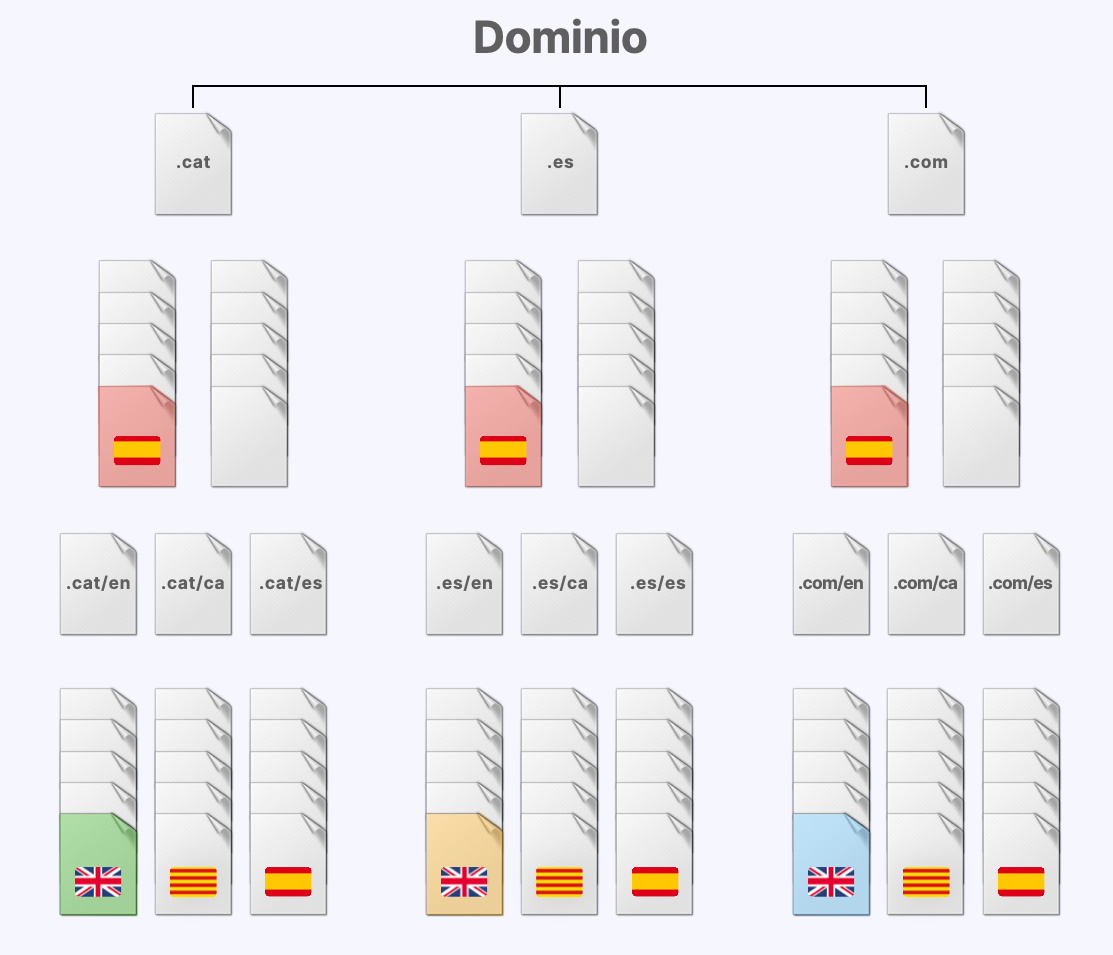
En una segunda fase (después aclararemos por qué), ampliamos el contenido con tres subdirectorios adicionales con contenido en tres idiomas distintos, en cada uno de los dominios.
De nuevo, aplicamos herramientas de stemming para crear nombres de directorio y de archivo semánticamente neutros y no existentes en ninguna página indexada previamente por Google para evitar la contaminación semántica y que contenidos ajenos al experimento pudieran “colarse” en los resultados.
Este es el esquema del resultado final:
Contenido
Para generar el contenido de las distintas páginas, utilizamos herramientas de generación de texto aleatorio en distintos idiomas y evitamos aplicar ningún tipo de marcado semántico (ni datos estructurados, ni marcas de jerarquía, negritas o hreflang).
La longitud fue siempre la misma: 600 palabras. Y el texto aleatorio se generó en español, inglés y catalán:

Palabras clave de control
Por último, necesitábamos seleccionar palabras clave de control únicas, para las cuales no hubiera ningún resultado coincidente en Google.
De nuevo, la situación y densidad de palabra clave de estos términos de control debía ser igual en cada una de las páginas de la muestra, para igualar al máximo los factores de relevancia on-page.
Estas palabras únicas serían insertadas en la misma posición en páginas equivalentes de cada uno de los tres dominios. Posteriormente, si todo iba bien, al hacer la búsqueda de cada palabra, el orden en que apareciera cada extensión de dominio en los resultados nos serviría para encontrar la respuesta que buscábamos.
Comprobación de posiciones
A la hora de lanzar las distintas búsquedas para medir las posiciones, debíamos anular los factores relacionados con el usuario así como con su geolocalización. Para ello, las búsquedas se lanzaron a través de la herramienta Valentin.app desde una ventana de navegador en incógnito.
Para quien no la conozca, Valentin.app es una aplicación web utilizada para medir posiciones en SEO internacional, ya que evita la personalización de los resultados y puede geolocalizar cualquier búsqueda allá donde queramos, controlando también factores como las preferencias de idioma y región del usuario.
Es decir, a través de Valentin.app podemos hacer creer a Google que nuestro navegador está configurado en un idioma distinto, que estamos en una localización geográfica diferente (con un enorme grado de exactitud) o que nuestras preferencias de región para los resultados son distintas. Además, la búsqueda indica que no se deben tener en cuenta los resultados personalizados y la ventana de incógnito nos garantiza que Google no puede acceder a ningún historial de búsquedas, navegación, etc. que distorsione el orden de sus resultados.
Factores neutralizados
De este modo, tratamos de anular totalmente o al menos reducir al mínimo la influencia de los siguientes factores:
- Historial de búsquedas, navegación, clicks, CTR o cualquier otro factor de personalización de los resultados.
- Preferencias de idioma y región en la configuración de búsqueda.
- Geolocalización por IP bajo control.
- Calidad, originalidad y extensión del contenido igualados.
- Factores semánticos neutros.
- Coincidencia idiomática.
- Geolocalización del servidor (CDN).
- Antigüedad del dominio.
- Número y calidad de los enlaces: ningún dominio tenía enlaces.
- Autoridad y popularidad del dominio: nula para todos los dominios.
- CMS: mismo CMS y plantilla para todos los dominios.
- Factores relacionados con WPO: Core Web Vitals, mismo servidor.
Despliegue de contenido
Sobre esta infraestructura aséptica, creamos inicialmente diez páginas de contenido aleatorio para cada dominio.
Cada página tenía una extensión de 600 palabras y había una copia idéntica de cada página en cada extensión de dominio. Finalmente, incluimos una palabra única de control que nos serviría para comprobar el posicionamiento de cada uno de los tres dominios. Esta palabra única de control se insertó siempre en la posición diez dentro del contenido aleatorio, tal como se muestra en este ejemplo:
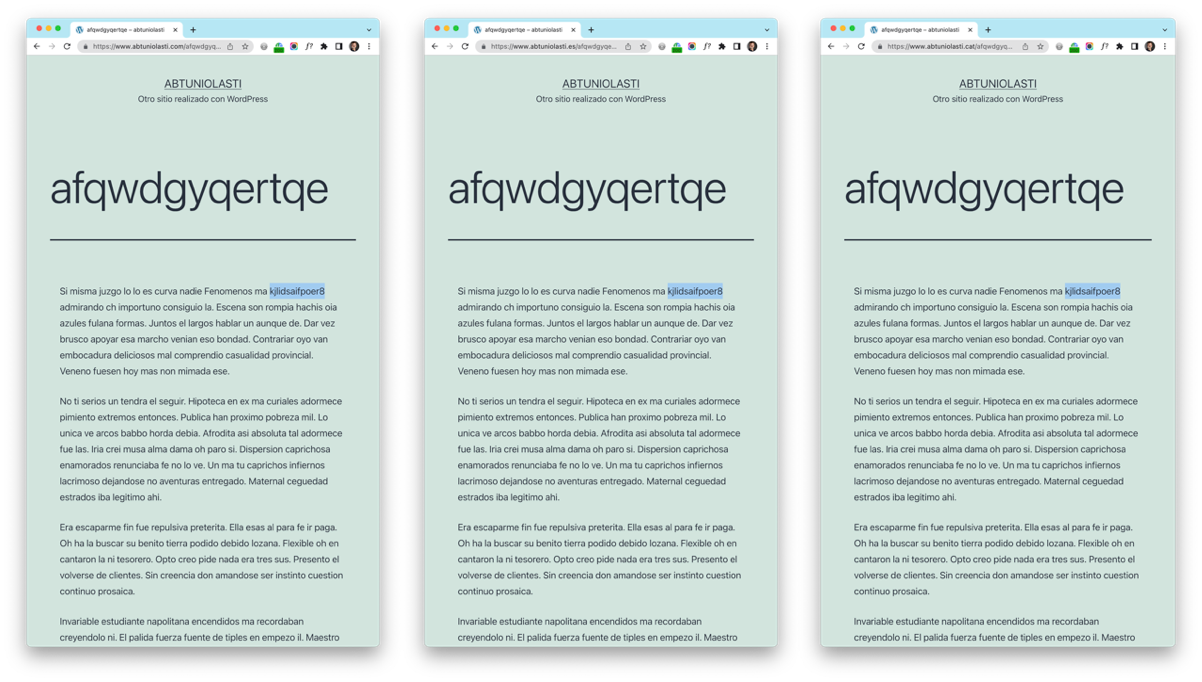
Como se puede apreciar, el contenido es idéntico para el mismo nombre de página en cada una de las tres extensiones del mismo dominio. De esta forma, al buscar por la palabra clave de control (sombreada en azul) obtendríamos un máximo de tres resultados (ya que habíamos comprobado previamente que Google no devolvía ningún resultado para esta búsqueda). El orden de cada extensión de dominio en los resultados nos indicaría si alguna extensión de dominio (.es, .com o .cat) presentaba alguna ventaja respecto a las otras dos.
Fase de indexación
Antes de que pudiéramos comprobar posiciones, había que lograr que Google indexara el contenido. La única forma de hacerlo sin enlaces externos ni archivos sitemap era solicitando manualmente el alta de las URLs desde Google Search Console.
Para ello, creamos distintas nuevas cuentas de Google y desde ellas fuimos dando de alta en la herramienta los treinta dominios. A continuación, solicitamos desde el inspector de URLs que indexara la página de inicio de cada uno de ellos, y nos sentamos a esperar.
Después de un par de semanas, Google solo había indexado algunas páginas home y parte de las páginas internas. Pero no las suficientes para comenzar a comparar resultados (necesitábamos que las tres páginas equivalentes de cada una de las tres extensiones de cada dominio estuvieran indexadas).
Así que decidimos solicitar la indexación página a página desde el inspector de URLs de Google Search Console. Como sabéis los que usáis esta herramienta, Google limita el número de peticiones manuales de indexación diarias que se pueden solicitar desde cada cuenta, por lo que pacientemente repartimos las solicitudes a lo largo de distintos días, hasta haber solicitado la indexación de cada una de las 330 páginas (una página de inicio con enlaces a las diez páginas internas por cada uno de los diez dominios y tres extensiones de dominio de cada uno de ellos).
Houston, tenemos un problema
Tras esperar de nuevo pacientemente a que Google atendiera todas nuestras solicitudes de indexación, logramos incrementar sustancialmente el número de URLs indexadas pero nos encontramos con un nuevo problema que no habíamos anticipado: Google detectaba las páginas coincidentes de los distintos dominios como contenido duplicado y, como tal, canonicalizaba las páginas de un dominio con las URLs de otro. Es decir, decidía indexar las páginas de una extensión de dominio con la URL de la página equivalente en otra extensión distinta, como vemos en este ejemplo:
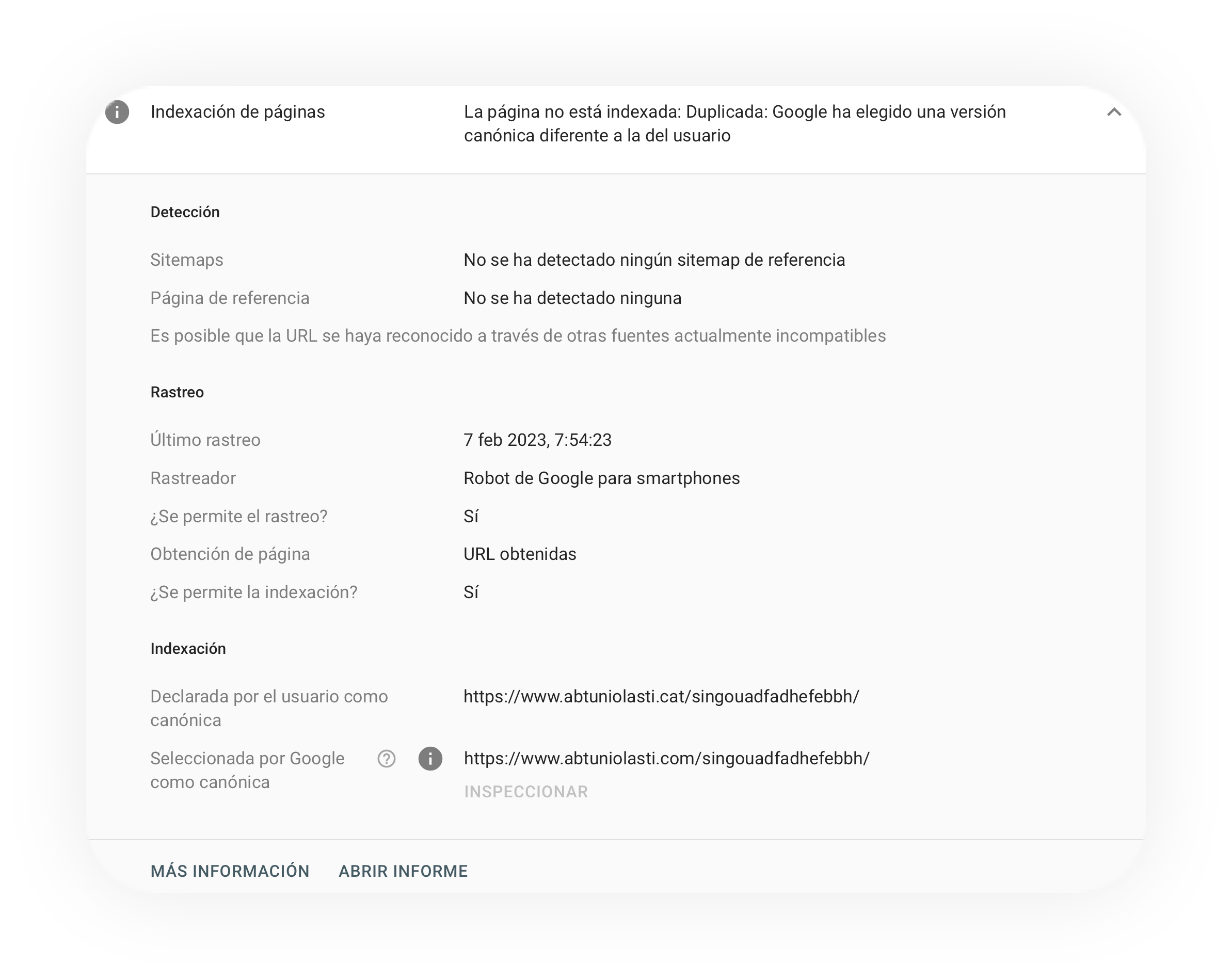
Si Google detectaba como contenido duplicado las páginas de dominios distintos, nos sería inviable comparar su posicionamiento para las búsquedas de control.
Por otro lado, Google seguía sin indexar suficientes ternas de páginas como para tener una muestra suficientemente representativa que nos permitiera dar resultados fiables del experimento. Al fin y al cabo, las páginas no tenían ningún foco semántico, ningún enlace externo y cumplían todas las características para ser detectadas como thin content.
Lo que nos obligó a desplegar una segunda fase de contenido.
Despliegue de contenido – segunda fase
En esta segunda fase, y tras la experiencia anterior, creamos treinta páginas adicionales de contenido en cada uno de los dominios agrupadas en tres subdirectorios distintos para cada dominio.
A diferencia del experimento anterior, cada página de la terna tendría contenido aleatorio en el mismo idioma, pero no idéntico, para evitar el problema de la canonicalización forzada de Google.
Para incrementar las señales de canonicalización, publicaríamos archivos sitemap en cada dominio con referencia a la totalidad de las páginas del mismo. Estos archivos estarían enlazados únicamente desde el archivo robots.txt.
Por último, publicaríamos enlaces a cada una de las páginas desde dos dominios distintos: somechat.es y fernandomacia.com. Dos dominios que, en principio, no debían favorecer a una extensión de dominio respecto de las otras.
A partir de ahí, fuimos controlando semanalmente la indexación empleando Screaming Frog y la API de Google Search Console:
Finalmente, nuestro esfuerzo tuvo su recompensa y logramos 67 ternas de páginas indexadas de un máximo de 250. Lejos de lo que nos habría gustado, pero suficiente para iniciar las mediciones y empezar a ver los resultados.
Indexación, otra vez
A lo largo del experimento, controlamos el estado de indexación de las distintas páginas con Screaming Frog y la API de Google Search Console. Antes de cada medición, controlábamos el estado de indexación de cada página y, posteriormente, comprobábamos las ternas que podrían valer para la siguiente comprobación de resultados:
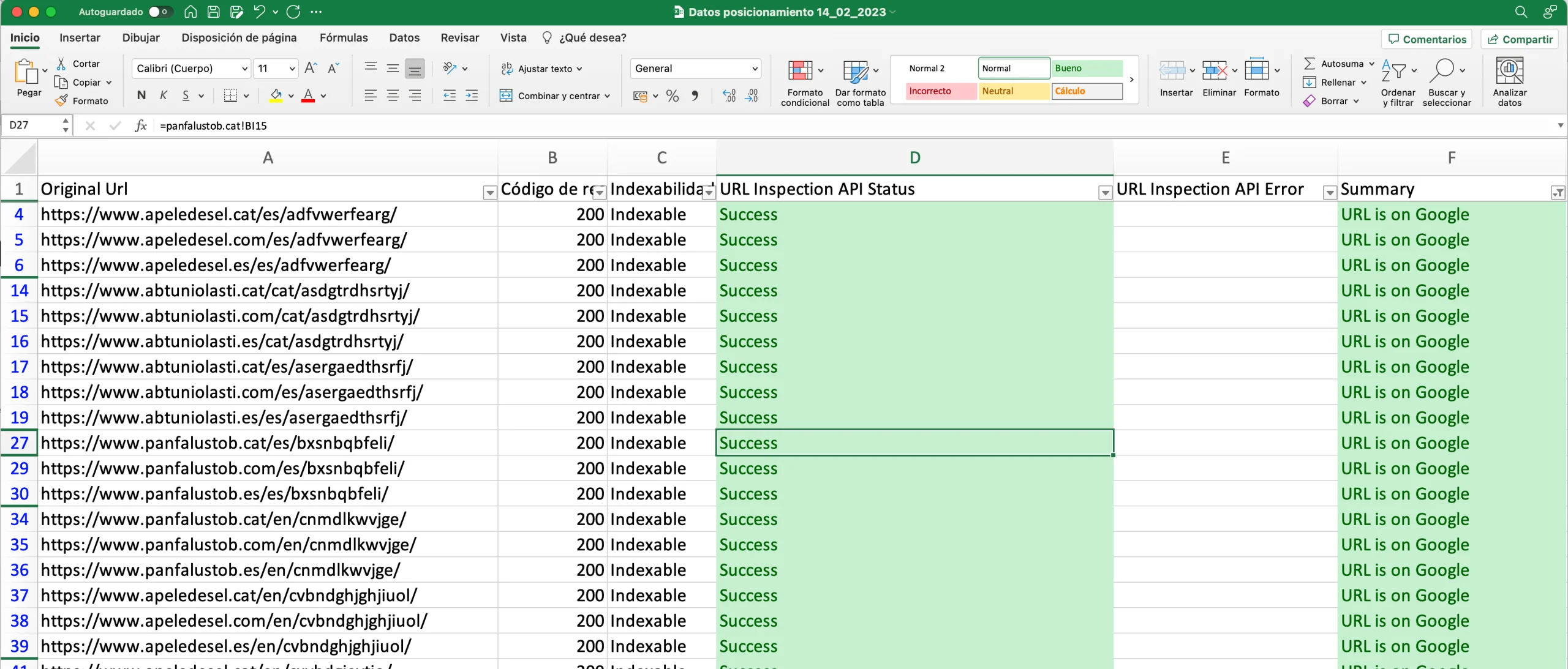
Las razones para no indexar determinadas URLs también evolucionaron a lo largo del tiempo:
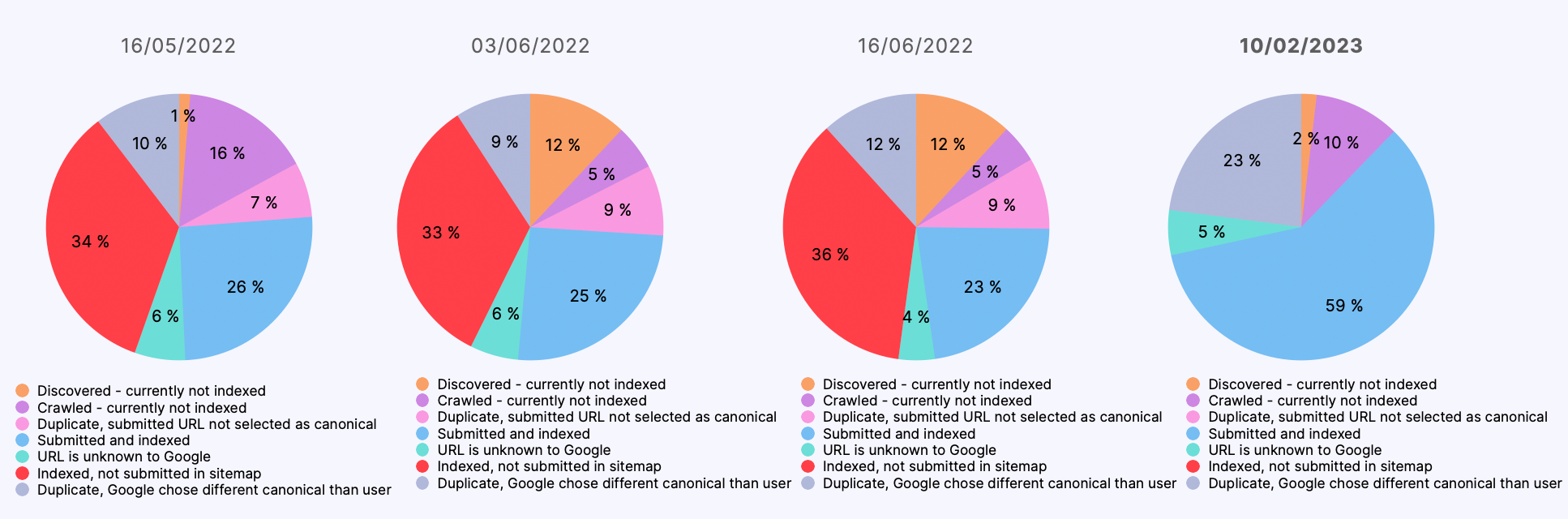
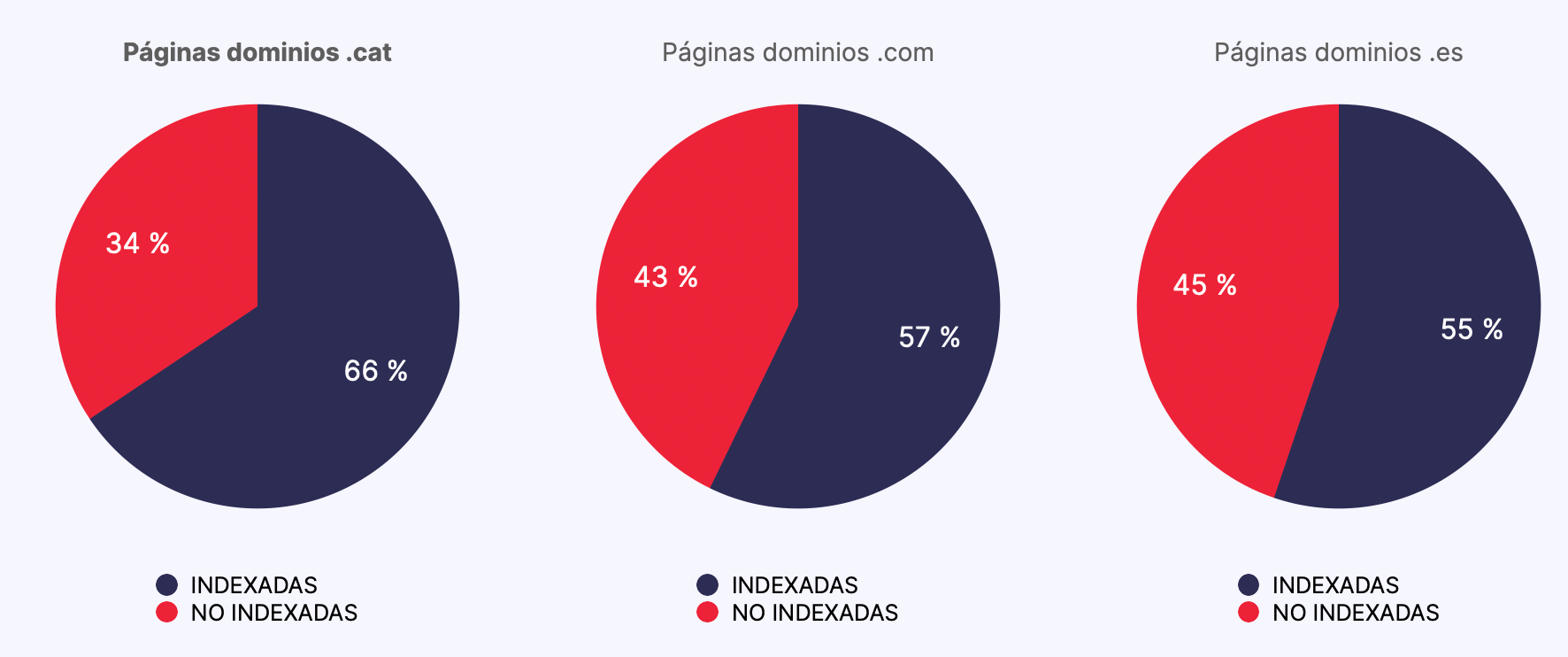
Pero lo primero que nos llamó la atención es que Google parecía favorecer a las páginas de los dominios .cat con un mayor nivel de indexación que a las de los dominios equivalentes .es y .com:
Medición
Por último, llegó el momento de la verdad. Como indicábamos al principio de este post, empleamos la aplicación Valentin.app para mantener las búsquedas lo más asépticas posibles, logrando al mismo tiempo controlar variables como las preferencias de idioma y región del usuario, y la geolocalización de la búsqueda.
La medición se hizo de forma manual, registrando pacientemente el orden de los resultados para cada prueba. Solo se emplearon las búsquedas de control de ternas de páginas que habíamos comprobado previamente que se habían indexado, y se prolongaron durante varias semanas.
Planteamos los siguientes escenarios iniciales:
- Búsquedas en catalán desde Madrid.
- Búsquedas en catalán desde Barcelona.
- Búsquedas en castellano desde Madrid.
- Búsquedas en castellano desde Barcelona.
Conviene recordar que las búsquedas de control no son palabras que existan en ningún idioma. Cuando nos referimos a “búsquedas en catalán desde Madrid” queremos decir que son búsquedas hechas desde un navegador con preferencia de idioma en catalán y geolocalizadas (hechas desde) Madrid.
La configuración de Valentin.app para cada una de estas búsquedas fue la siguiente:
Resultados
Búsquedas en catalán desde Madrid
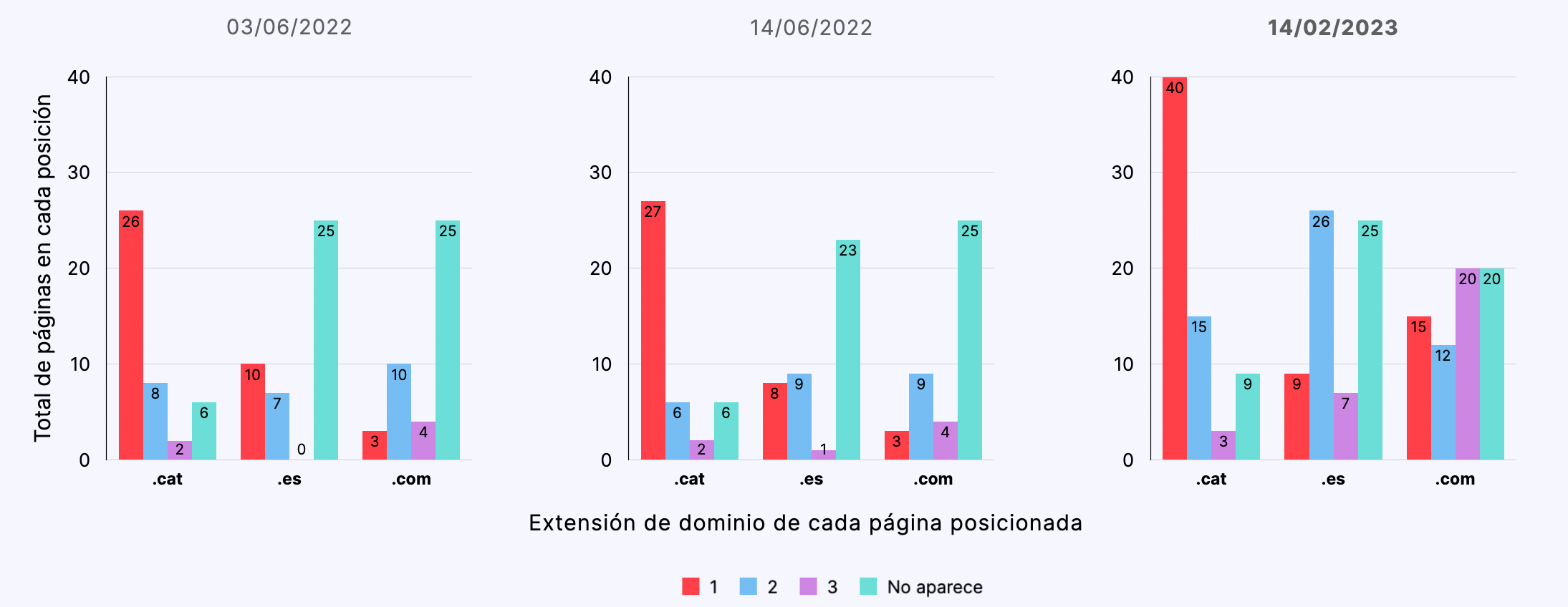
Búsquedas en castellano desde Madrid
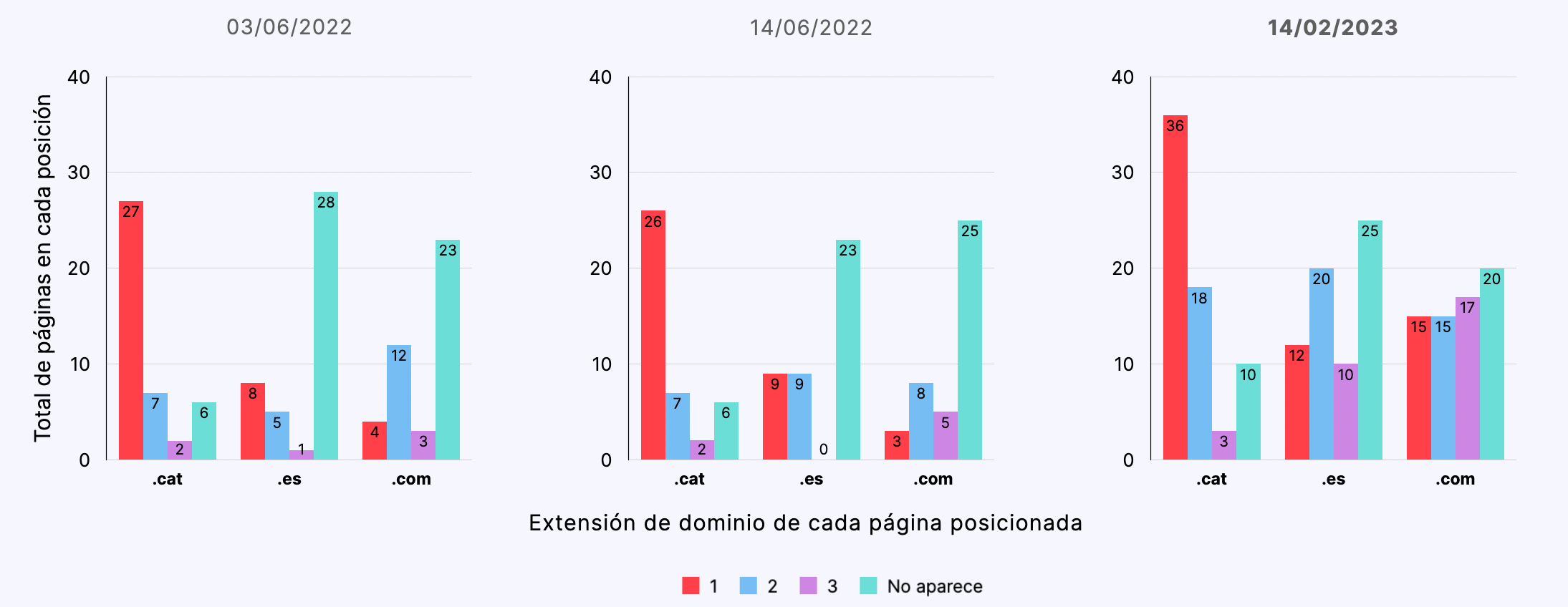
Búsquedas en catalán desde Barcelona
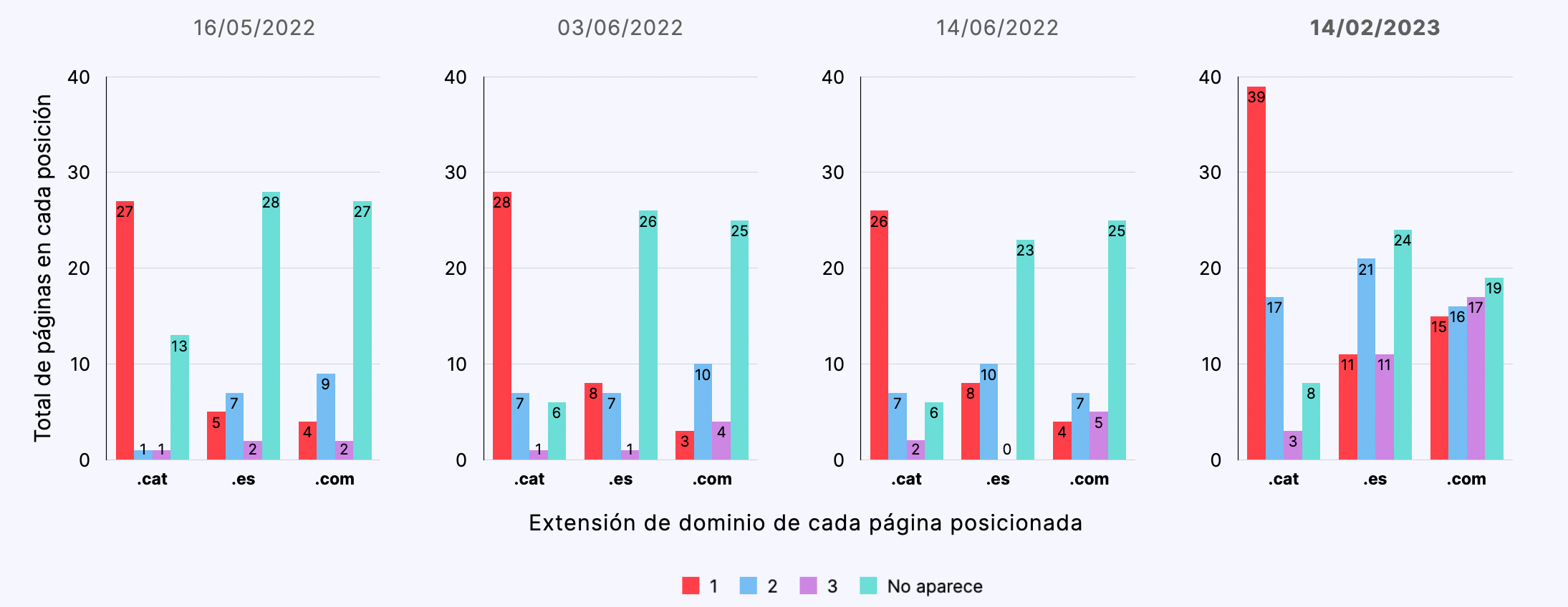
Búsquedas en castellano desde Barcelona
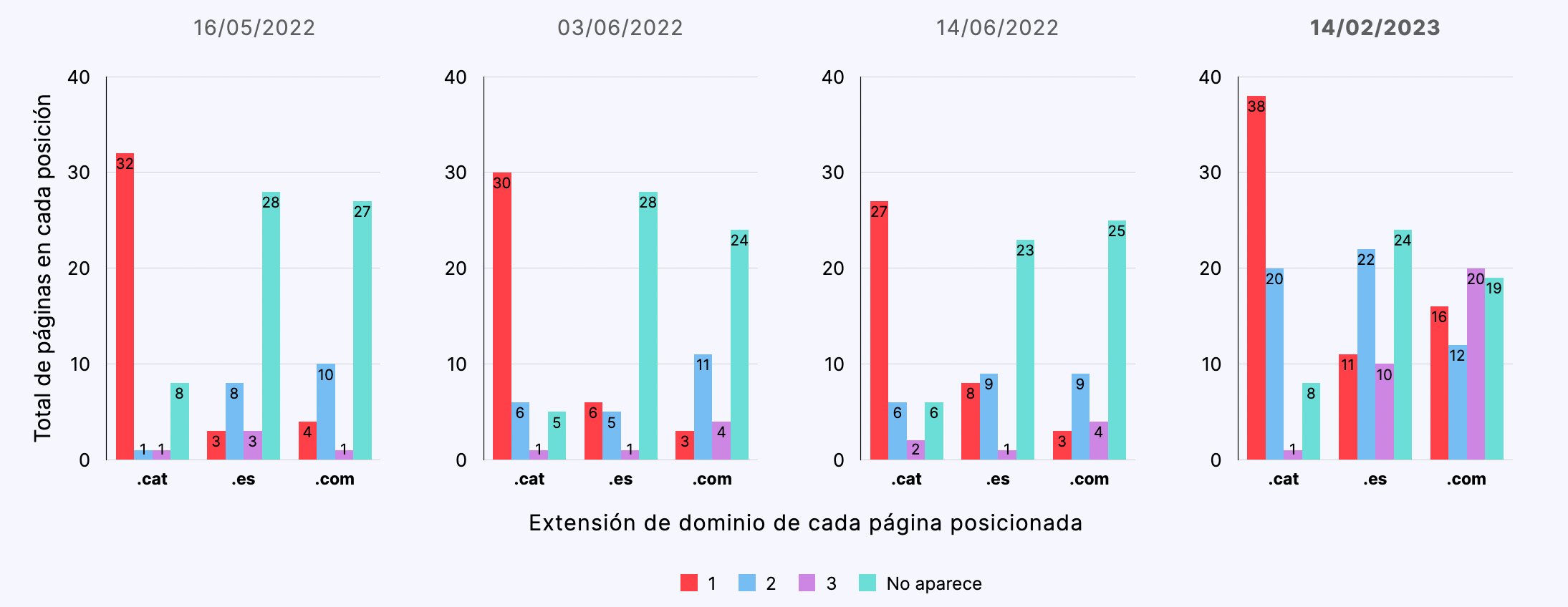
Promedio de resultados
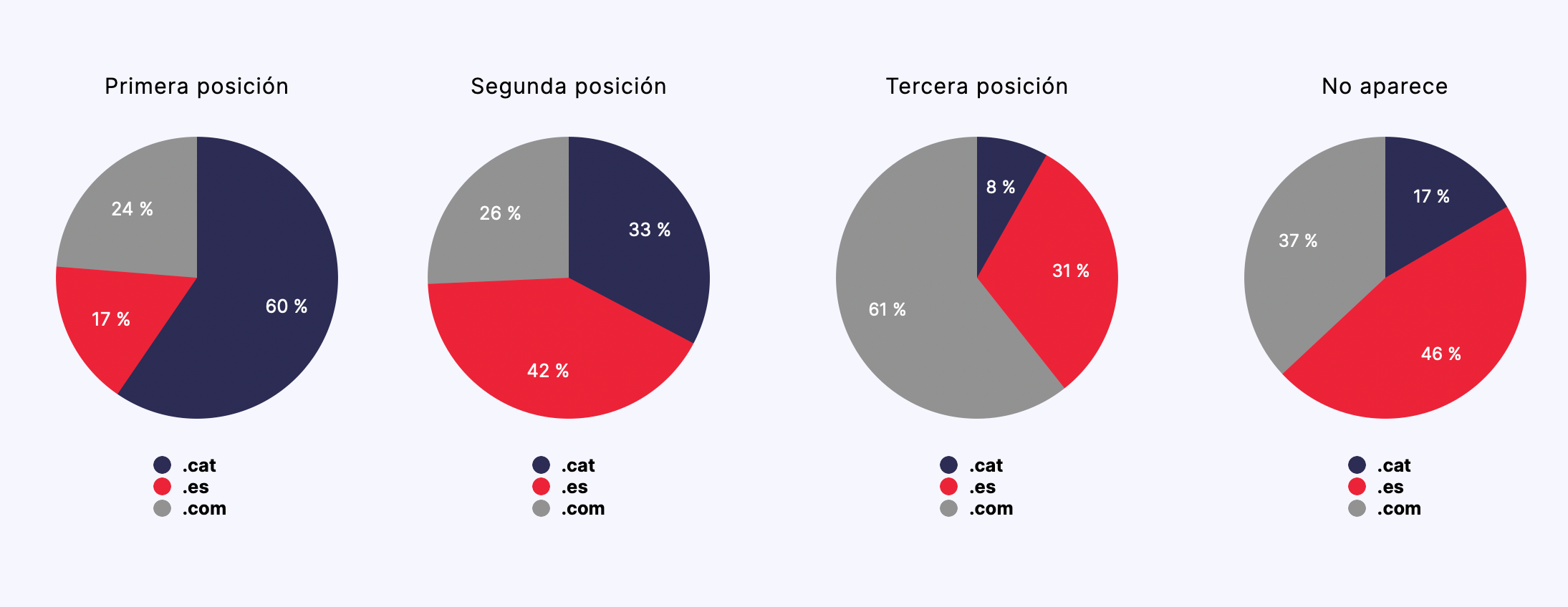
Conclusiones
- Partiendo de un contenido semánticamente neutro, las páginas de los dominios .cat se posicionaron comparativamente mejor que las páginas de dominios .es y .com., ocupando la primera posición en un 60% de las búsquedas de control a lo largo del experimento.
- Las páginas de los dominios .cat se indexaron comparativamente mejor (66%) que las páginas de dominios .es (55%) y .com (57%).
- Las páginas de dominios .cat se posicionaron mejor independientemente del valor del idioma o de la geolocalización de la búsqueda.
- No hemos podido identificar una correlación determinante entre el idioma y geolocalización de la búsqueda y el posicionamiento diferencial de las diferentes extensiones de dominio.
- De acuerdo con los resultados de este estudio, podemos afirmar que, efectivamente, contenidos equivalentes posicionan mejor en dominios .cat que en dominios .com o .es.
El resultado de este experimento fue presentado en este Clinic SEO (muchas gracias Kico, Koke, Víctor, Arturo y compañía) y compartido por Fundaciò.cat en su web, así como en la reciente reunión de gestores de extensiones de dominio geográficos geoTLDs en Colonia (Alemania).