

Escrito por Ramón Saquete
Índice
El shadow DOM es difícil de indexar, ya que sólo se puede crear con JavaScript y no existe una forma de declararlo en el HTML. Sin embargo, es una tecnología muy útil para facilitar el trabajo de los desarrolladores, por lo que cada vez es más frecuente encontrarlo en nuevos desarrollos. Aquí veremos qué es el shadow DOM, qué problemas genera a la indexación y cómo se puede intentar hacer indexable.
Antes de entrar en materia, recordemos qué son los web components: estos engloban varias tecnologías, entre las que se incluye el shadow DOM.
Web components
El shadow DOM es una de las tecnologías que ya comentamos hace años que usan los web components. Desde entonces, la especificación ha evolucionado de los web components v0 (que sólo eran compatibles con Chrome mientras y requerían polyfills o frameworks para otros navegadores), a los web components v1, que son compatibles con todos ellos.
Los web components no aportan nada nuevo al usuario, pero son una excelente forma de aislar partes del código de una web, facilitando el trabajo en paralelo de distintos desarrolladores en el front end. Los componentes evitan que el código de un desarrollador afecte al código de otro, al permitir su encapsulación, gracias a que el código CSS y JavaScript dentro del shadow DOM, queda aislado del resto de la página, dentro de una nueva etiqueta HTML o custom element, definida con el nombre que quiera darle el programador. Por ello esta tecnología, aparece cada vez con más frecuencia en los nuevos desarrollos, como se puede ver en la siguiente gráfica, donde se muestra el uso de los custom elements en Chrome, que es una de las tecnologías base que forman los web components:
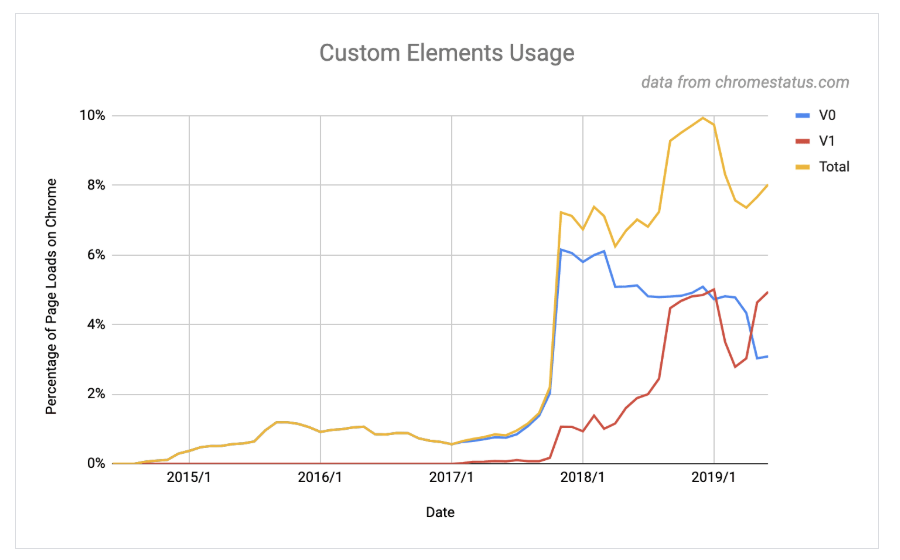
No se debe confundir este tipo de componentes con los componentes de un framework como Vue, Angular JS o React, ya que estos sustituyen directamente el componente por código HTML en el light DOM y pueden hacerlo en el servidor utilizando su versión universal, por lo que no plantean tantos problemas de indexabilidad como los auténticos web components.
Diferencia entre light DOM, shadow DOM y composed DOM
En materia de indexabilidad, el light DOM es la parte del componente visible en el código sin ejecutar JavaScript y por tanto, indexable. Por otro lado, el shadow DOM es la parte de la implementación que queda oculta y crea el desarrollador mediante JavaScript y, cómo ya sabemos, Google no siempre tiene render budget para ejecutar el JavaScript de las páginas que indexa, por lo que Google recomienda que siempre que sea posible, el contenido a indexar esté en el light DOM.
El composed DOM es la mezcla de ambos, ya que en el shadow DOM podemos definir huecos, llamados slots, en los que podemos asignar trozos del light DOM.
Veámoslo con un ejemplo: supongamos que tenemos un web component (estos se reconocen porque usan una etiqueta HTML que lleva un guión en el nombre, en este caso «mi-componente»). Así se vería el código HTML de este componente, sin ejecutar JavaScript,:
<mi-componente>
<span slot="titulo">Título en el light DOM pero con H3 en el shadow DOM</span>
<p>Texto en el light DOM</p>
</mi-componente>
Además, suponemos que el componente tiene una plantilla declarada de la siguiente forma, en la que existe un slot o hueco con el nombre «titulo» y otro, inicialmente sin nombre, que cogerá el contenido del componente que no tenga asignado ningún nombre de slot:
<slot></slot> <h3><slot name="titulo"></slot></h3> <p>Texto en el shadow DOM</p>
Si ejecutamos JavaScript en el componente anterior, el navegador generará el siguiente código, que es el shadow DOM compuesto con el light DOM, es decir, el composed DOM:
<p>Texto en el light DOM</p> <h3>Título en el light DOM pero con H3 en el shadow DOM</h3> <p>Texto en el shadow DOM</p>
En este caso, si Google no ejecuta JavaScript, no sabrá que el título usa una etiqueta h3, no verá el párrafo que pone «Texto en el shadow DOM» y rastreará el texto en otro orden, perjudicando al posicionamiento de la página que use este componente, al no poderle dar importancia suficiente al encabezado y perder parte del contenido y el orden del mismo.
¿Cómo saber qué partes de un web component están en el shadow DOM?
Si desactivamos JavaScript en una página, no veremos nada que esté en el shadow DOM o requiera JavaScript, pero si queremos saber específicamente qué partes de un componente están en el shadow DOM, podemos usar la herramienta de inspeccionar elemento, con JavaScript activado, y el navegador nos mostrará el shadow DOM y el light DOM por separado, dándole un sombreado al primero. Ejemplo:
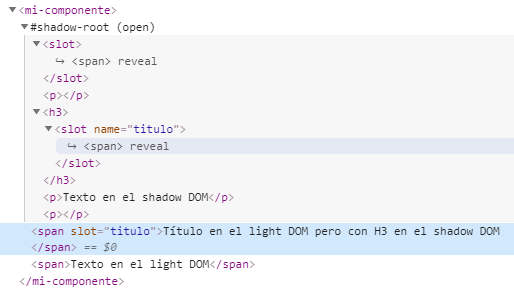
En esta captura de Google Chrome, donde vemos el componente del ejemplo anterior con la herramienta inspeccionar elemento, se aprecia que el shadow DOM aparece englobado dentro de la etiqueta #shadow-root, indicando que es la raíz del shadow DOM. Además, si pinchamos dentro de un slot, nos destaca el HTML asociado en el light DOM.
¿Cómo hacer indexable el shadow DOM?
Actualmente, la única forma de hacer indexable el Shadow DOM es usar una técnica denominada rehidratar el DOM. Se trata de ejecutar código en el servidor que calcule el composed DOM del componente tal y como lo haría el navegador, para reemplazar dicho componente por éste código. De esta forma, todo se queda generado en el HTML creado en el servidor antes de llegar al cliente. Una librería JavaScript que implementa esta técnica es skatejs. No obstante y dependiendo del web component, esta solución podría dar problemas.
Otra opción es, como sugiere Google, llevar todo el contenido susceptible de afectar al posicionamiento al light DOM. Pero esto lo podemos hacer solo en determinados casos. Por ejemplo: si el componente es un botón que realiza una acción, como compartir la página en una red social, no es necesario ni siquiera que tenga light DOM. Si, por el contrario, es un componente que le da formato a un bloque de preguntas y respuestas, puede ser más problemático, sobre todo si queremos mantener en el light DOM el marcado semántico de los encabezados y otras etiquetas semánticas de HTML, y que los estilos de la página no afecten a estas etiquetas.
Conclusiones
Los web components son muy útiles para el desarrollo a medida y, si su uso se extiende a los CMS, se podrá aislar mejor el código de distintos plugins, para evitar incompatibilidades. Sin embargo, para asegurar la indexabilidad de las páginas, debemos o bien no utilizar web components o bien llevar todo el código importante al light DOM del componente u obligar a los desarrolladores a utilizar la compleja solución de rehidratar el DOM.
Ninguna de estas aproximaciones es buena, porque se pierde la capacidad de encapsulación del código, que es la principal razón para usar web components. Por lo que es de esperar que en un futuro la especificación evolucione para permitir declarar el shadow DOM en el HTML de forma explícita e indexable.



