

Escrito por Ramón Saquete
 Los buscadores o, como se les llama técnicamente, Sistemas de Recuperación de Información, son uno de los grandes logros de las ciencias de la computación y, más concretamente, del campo de la Inteligencia Artificial. Hoy en día, nadie puede poner en duda su importancia como motor de la economía mundial. Para muchos, su funcionamiento interno es un misterio casi mágico. En esta serie de artículos desvelaré parte de esa magia.
Los buscadores o, como se les llama técnicamente, Sistemas de Recuperación de Información, son uno de los grandes logros de las ciencias de la computación y, más concretamente, del campo de la Inteligencia Artificial. Hoy en día, nadie puede poner en duda su importancia como motor de la economía mundial. Para muchos, su funcionamiento interno es un misterio casi mágico. En esta serie de artículos desvelaré parte de esa magia.
Si eres desarrollador Web, después de leer la serie de artículos que voy a desarrollar, sabrás implementar un buscador en una Web, más allá del típico e ineficiente buscador que sólo busca coincidencias en la base de datos y no proporciona resultados ordenados por relevancia. Si eres consultor SEO, comprenderás un poco mejor el funcionamiento interno de los buscadores.
Con el fin de llegar al mayor número de lectores, voy a intentar expresarme de la forma menos técnica posible, no obstante, y puesto que este es un tema de alto nivel, en algunos casos usaré fórmulas matemáticas. En estos casos, aquellos que no las dominen , pueden saltar directamente a la explicación. Sin embargo, aquellos que sí sean duchos en esta materia, tendrán un conocimiento mucho más profundo de lo que explico, ya que una fórmula puede valer por mil palabras.
 Empecemos poniéndonos en situación. Dentro de la Informática, el campo de la Inteligencia Artificial está dividido en muchas ramas como: Reconocimiento de Formas, Robótica, Visión Artificial, Procesamiento del Lenguaje Natural, etc. Aquí nos vamos a centrar en una de las aplicaciones del Procesamiento del Lenguaje Natural, los Sistemas de Recuperación de Información, que a partir de ahora llamaré por sus siglas en inglés IRS. Ésta, al igual que otras aplicaciones de esta rama, como la Traducción Automática, los Sistemas de Búsqueda de Respuesta, los Sistemas de Diálogo o los Sistemas de Extracción de Información, suponen para los investigadores que las desarrollan, áreas en la que es necesario especializarse, ya que a su vez, están dividas en muchos sub-problemas bastante complejos. Por otro lado, existe el área llamada Inteligencia Web, que consiste en aplicar técnicas de Inteligencia Artificial a una Web.
Empecemos poniéndonos en situación. Dentro de la Informática, el campo de la Inteligencia Artificial está dividido en muchas ramas como: Reconocimiento de Formas, Robótica, Visión Artificial, Procesamiento del Lenguaje Natural, etc. Aquí nos vamos a centrar en una de las aplicaciones del Procesamiento del Lenguaje Natural, los Sistemas de Recuperación de Información, que a partir de ahora llamaré por sus siglas en inglés IRS. Ésta, al igual que otras aplicaciones de esta rama, como la Traducción Automática, los Sistemas de Búsqueda de Respuesta, los Sistemas de Diálogo o los Sistemas de Extracción de Información, suponen para los investigadores que las desarrollan, áreas en la que es necesario especializarse, ya que a su vez, están dividas en muchos sub-problemas bastante complejos. Por otro lado, existe el área llamada Inteligencia Web, que consiste en aplicar técnicas de Inteligencia Artificial a una Web.
¿Qué es un IRS?
Los IRS son herramientas que, a partir de una consulta, son capaces de escoger dentro de una enorme colección de documentos, los que responden a esa consulta y ordenarlos por relevancia.
Si buscáis artículos científicos referentes a Information Retrieval encontraréis mucha más información de la que voy a dar aquí, pero claro, normalmente con explicaciones menos didácticas. Google tiene varios artículos sobre IR, de sus investigadores, publicados en:
https://research.google.com/pubs/InformationRetrievalandtheWeb.html
Para poder realizar la colosal hazaña que he descrito, sobre millones de documentos y en pocos segundos, simplificando mucho y sin tener en cuenta muchos aspectos técnicos, se llevan a cabo las siguientes tareas:
- Indexación:
- Primero se pre-procesan los documentos para analizarlos y aplicar transformaciones que después mejoren la búsqueda.
- Seguidamente se calculan los pesos de los términos extraídos en el paso anterior y se almacenan de forma eficiente en un índice.
- Tratramiento de la consulta:
- Se analiza la consulta para representarla internamente de una forma que permita compararla con los documentos.
- Comparación entre la consulta y la colección de documentos
- Se obtiene un valor que indica la relevancia que tiene cada documento para la consulta y que va a permitir ordenarlos.
En este artículo explicaré sólo la fase de Indexación y en el siguiente las otras dos.
Indexación
Pre-procesado del documento
Como ya he comentado, primero hay que analizar el documento. Para realizar esta tarea se eliminan las etiquetas HTML, extrayendo primero su significado, para saber cuál es la importancia que aportan esas etiquetas a las palabras que contienen.
En el proceso se va contando el número de apariciones de cada palabra, puesto que, a partir de ese valor, se calculará la importancia de la palabra en el documento, ya que si aparece más veces, será más probable que el documento sea más relevante para esa palabra.
Al mismo tiempo se suele calcular la posición de la palabra en el documento, puesto que si las palabras que buscamos están más juntas en él, será más probable que ese sea un documento relevante para la consulta. Así que teniendo almacenada la posición, podremos calcular la distancia entre esas palabras de la consulta en el documento, para tenerlo en cuenta.
Algunos IRS en lugar de indexar las palabras indexan su raíz, para poder considerar las derivaciones de una misma palabra (por ejemplo, tiempos verbales), como repeticiones del mismo término. El cálculo de la raíz se suele hacer mediante algún algoritmo heurístico que intenta adivinar la raíz correcta. El más usado en inglés es el Stemmer, de Martin Porter, que tiene su adaptación al Español en el software Snowball.
La estrategia de indexar la raíz de las palabras tiene el problema de que las palabras sinónimas son consideras palabras distintas, por eso otros IRS agrupan la frecuencia de aparición de las palabras por sentido. Para ello, es necesario resolver uno de los problemas más difíciles y estudiados en procesamiento del lenguaje natural, el WSD (Word Sense Desambiguation), que trata de desambiguar el sentido de las palabras por su contexto.
Otra estrategia es indexar conjuntos de dos o más palabras en lugar de palabras sueltas, para afinar mucho mejor la intención de búsqueda del usuario. Como esto requiere un tamaño de índice mucho mayor, en estos casos sólo se tienen en cuenta los conjuntos de palabras más frecuentes.
¿Qué hace Google? Nadie lo sabe, puede que utilice todas las estrategias anteriores o puede que ninguna y use n-gramas en su lugar. Lo que sí podemos saber por los resultados de búsqueda es que tiene en cuenta sinónimos y la cercanía de las palabras clave de la consulta, funcionalidades que puede lograr de muchas formas distintas.
También hay una cosa que, mirando los resultados, podemos saber que no hace Google, que es eliminar las stop words. Las stop words, son palabras que tienen frecuencias de aparición muy altas en los documentos, como los artículos y las preposiciones. Puesto que éstas son palabras que no aportan información relevante sobre el documento e incrementan significativamente el tamaño del índice, son descartadas normalmente en todos los IRS. Google no las elimina porque, a veces, pueden aportar información a la consulta, por ejemplo «país» y «el país» son búsquedas con distinta intención.
Cálculo del peso de las palabras o términos
En los IRS para representar los documentos y las consultas, normalmente, se utiliza el modelo espacio vectorial, porque es el que mejores resultados obtiene. Esto quiere decir que vamos a representar los documentos y la consultas de los usuarios numéricamente en un espacio vectorial n-dimensional, con tantas dimensiones como palabras tengan. Si de momento no entendéis la frase anterior, no os preocupéis, en la próxima entrada prometo explicarlo con más detalle. Lo que importa ahora es que vamos a calcular el peso o la importancia que tiene cada palabra a la hora de devolver los resultados ordenados por relevancia. Para esta tarea, normalmente, se utiliza la fórmula de Gerard Salton, llamada TFIDF (Term Frequency – Inverse Document Frequency). Esta fórmula se calcula multiplicando la frecuencia del término en el documento por la frecuencia inversa del término en la colección de documento, que en seguida explicaré.
Es lógico pensar que si una palabra aparece más veces en un documento, hará que ese documento sea más relevante en una consulta que contenga esa palabra, por eso el primer elemento de la fórmula es la frecuencia del término en el documento, que podemos usarla tal cuál la hemos obtenido en el paso anterior o normalizarla dividiendo por la frecuencia del término que más veces apareció en el documento. De esta forma las frecuencias de los términos de todos los documentos siempre estarán entre 0 y 1. Así evitaremos que documentos largos tengan preferencia sobre los documentos cortos, aunque en la práctica siempre tendrán algo más de peso los largos.
Fórmula:
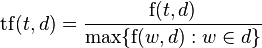
En el denominador tenemos el máximo de todas las frecuencias de los términos w pertenecientes al documento d.
Para aquel al que le interese profundizar, esta no es una de las mejores maneras de normalizar para obtener resultados más justos, hay normalizaciones no lineales, mucho mejores, como la normalización pivotada de Amit Singhal.
Si la palabra aparece en muchos documentos de la colección, esa palabra será menos determinante para devolver resultados relevantes y si aparece en pocos documentos, hará que esos documentos sean más relevantes. Esa es la idea de la frecuencia inversa de la palabra en la colección de documentos y se calcula dividiendo el número de documentos de la colección entre el número de documentos que contiene el término. Al resultado se le aplica un logaritmo para hacer que los valores altos no crezcan demasiado y así normalizarlos un poco.
Fórmula:
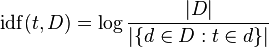
Finalmente, podemos calcular la TFIDF que nos dará por fin el peso de la palabra. Esto es la importancia del término a la hora de decidir los resultados de búsqueda, que viene dado por la importancia de la palabra t, en el documento d, por la importancia de la palabra en la colección D:
![]()
Ahora ya tenemos toda la información necesaria para elaborar el índice inverso, que estará compuesto por un listado de palabras y, para cada una, tendremos un listado de identificadores de los documentos donde aparecen junto con sus pesos (TFIDF).

De esta forma, cuando llegue una palabra podremos saber rápidamente en qué documentos está y qué peso tiene la palabra en éstos, para poder elaborar una fórmula que nos ordene los documentos por relevancia. Esta fórmula y varias cosas más, las terminaré de explicar el mes que viene en mi próxima entrada, espero que no dejéis de leerla y comentarla.



Me ha gustado, claro y simple.
Gracias.
Gran trabajo amigo, muchas gracias por el aporte. Saludos
Buenas tardes Ramón! Muy didáctico para quienes no somos matemáticos ni informático pero trabajamos en social media. Espera la siguiente parte! Gracias!